详细说明¶
工作流编辑页面包含三部分,分别为设置面板、节点面板以及编辑面板。设置面板 用于设置工作流应用的基本信息以及运行配置;节点面板 用于列出工作流可用的节点列表;编辑面板 用于编辑、预览工作流,以及设置节点具体执行逻辑。如下图所示:
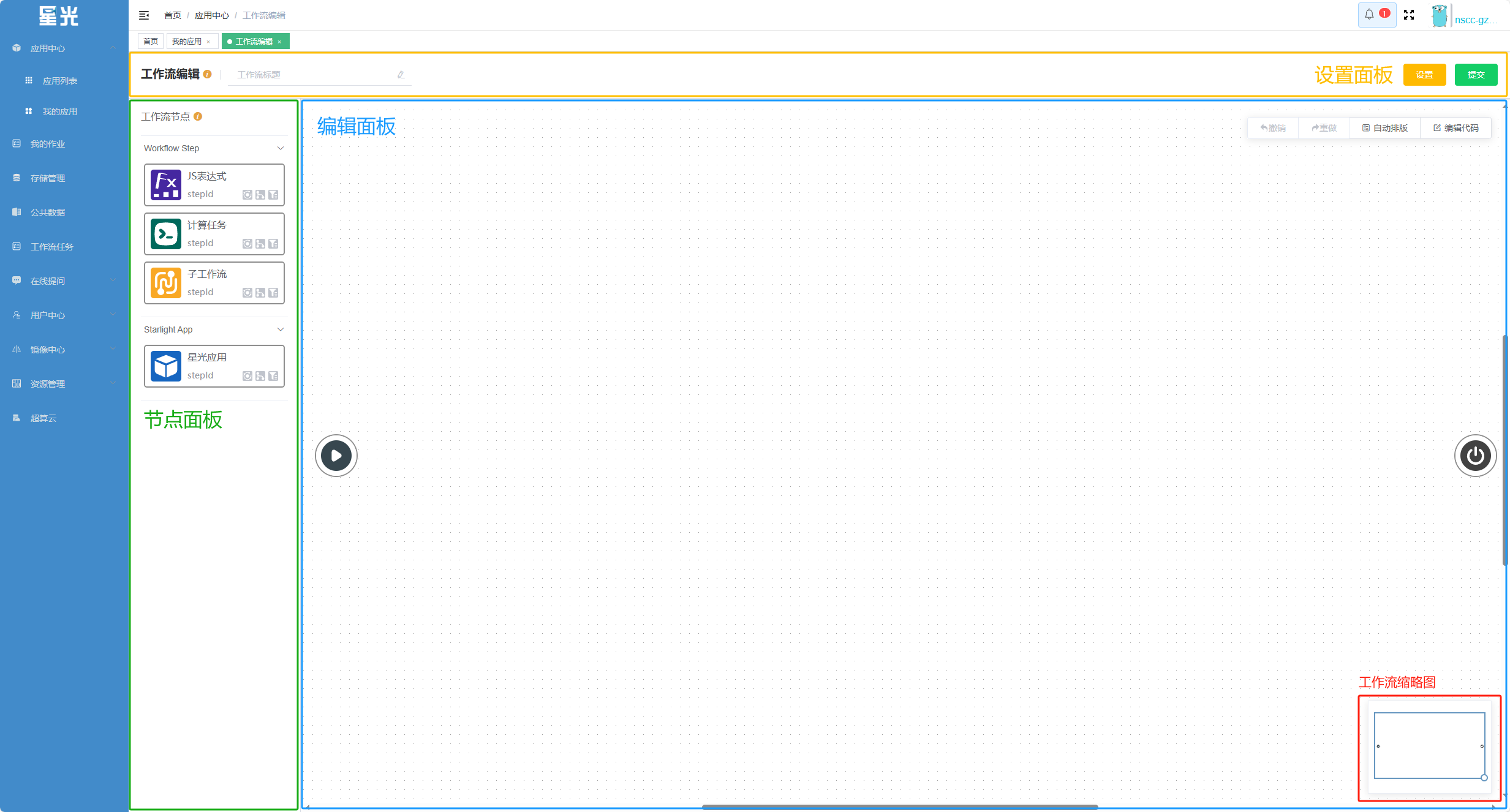
工作流节点¶
节点是工作流的基本组成。将节点根据其输入、输出的依赖关系连接起来,组成一个工作流。
要在工作流添加一个节点,只需要在左侧节点面板中选择所需类型的节点(点击并摁住鼠标左键),将节点框拖拽至右侧的编辑面板中释放鼠标左键,并定义该节点的 ID 即可。
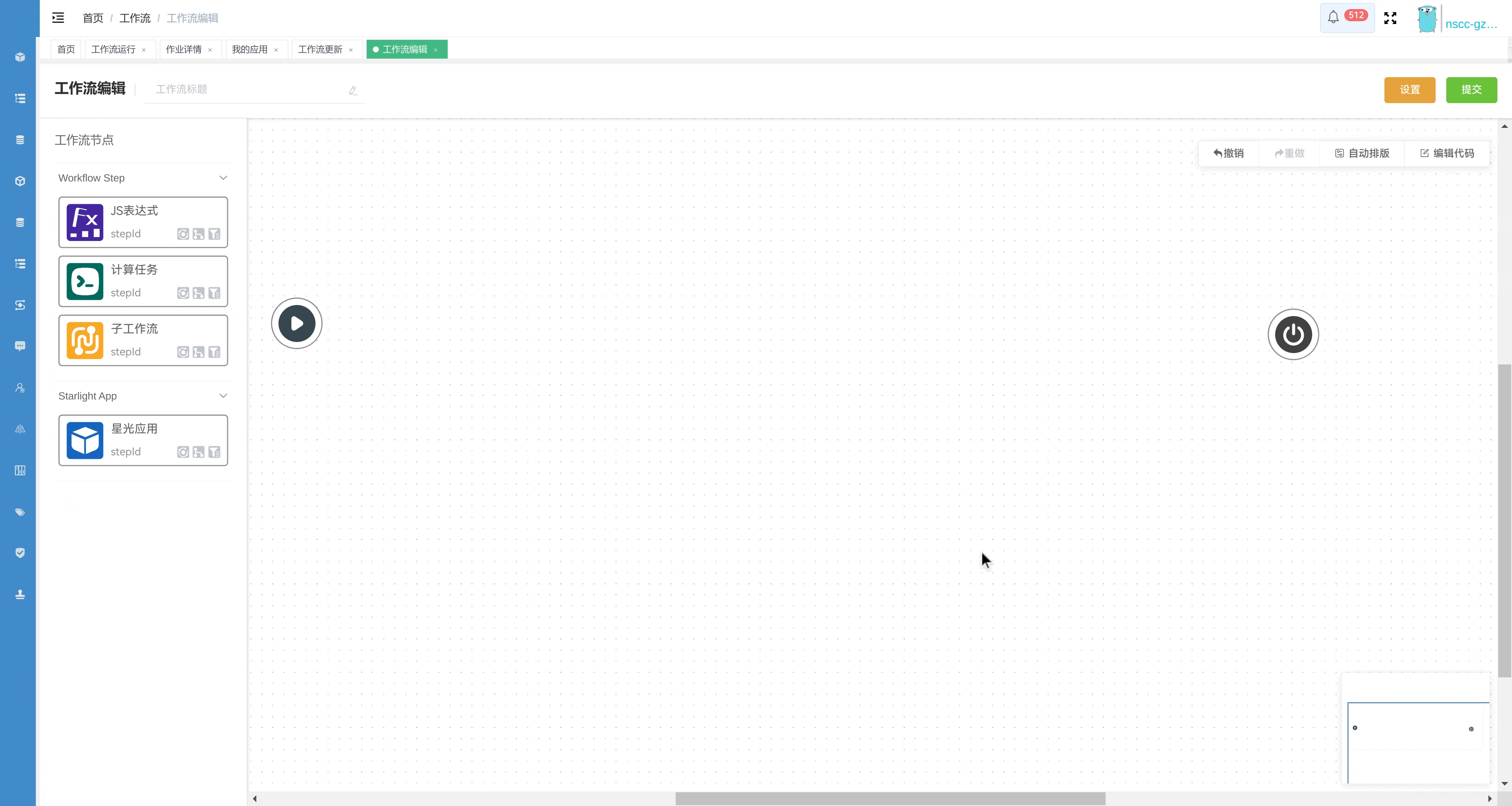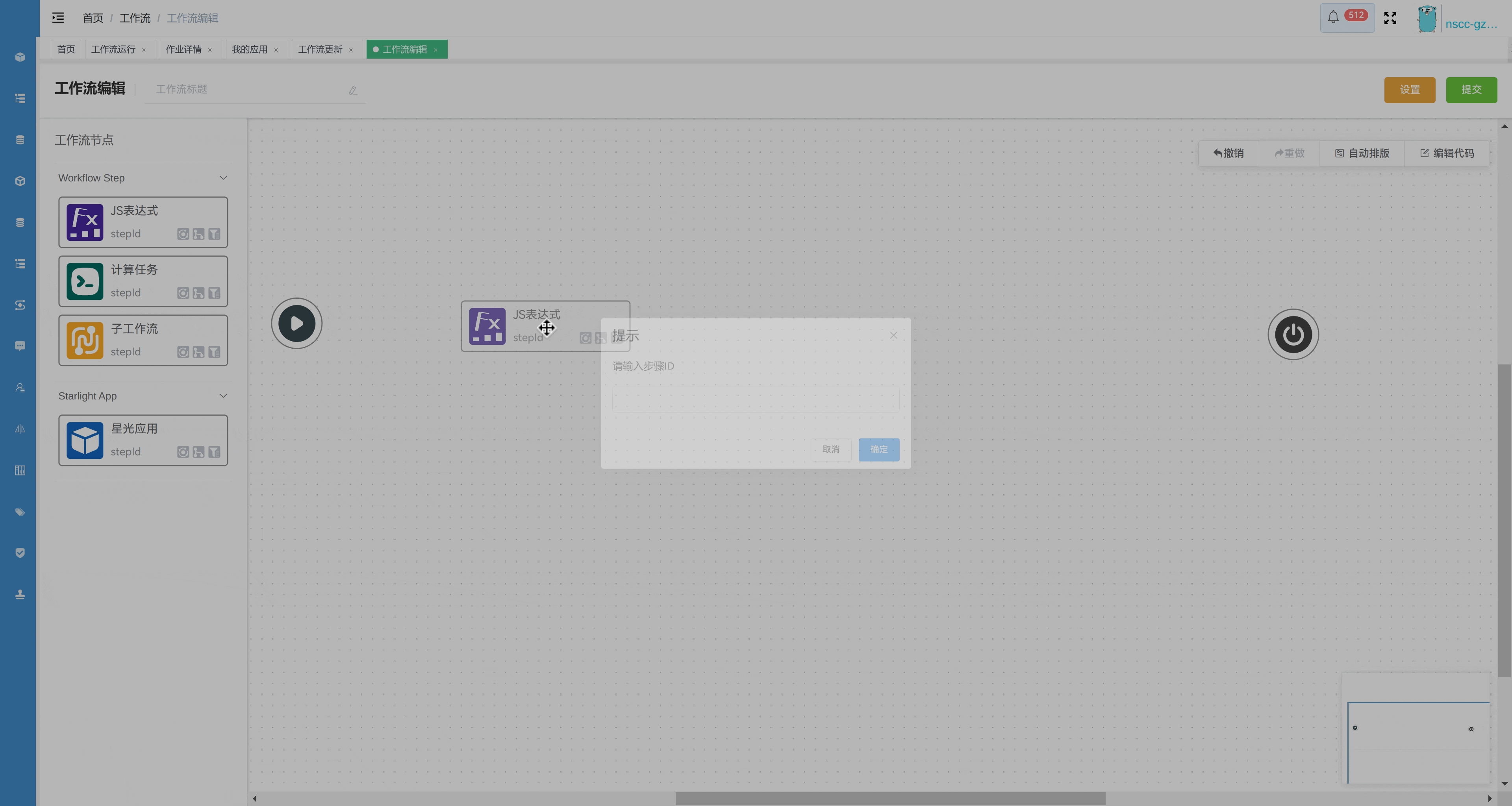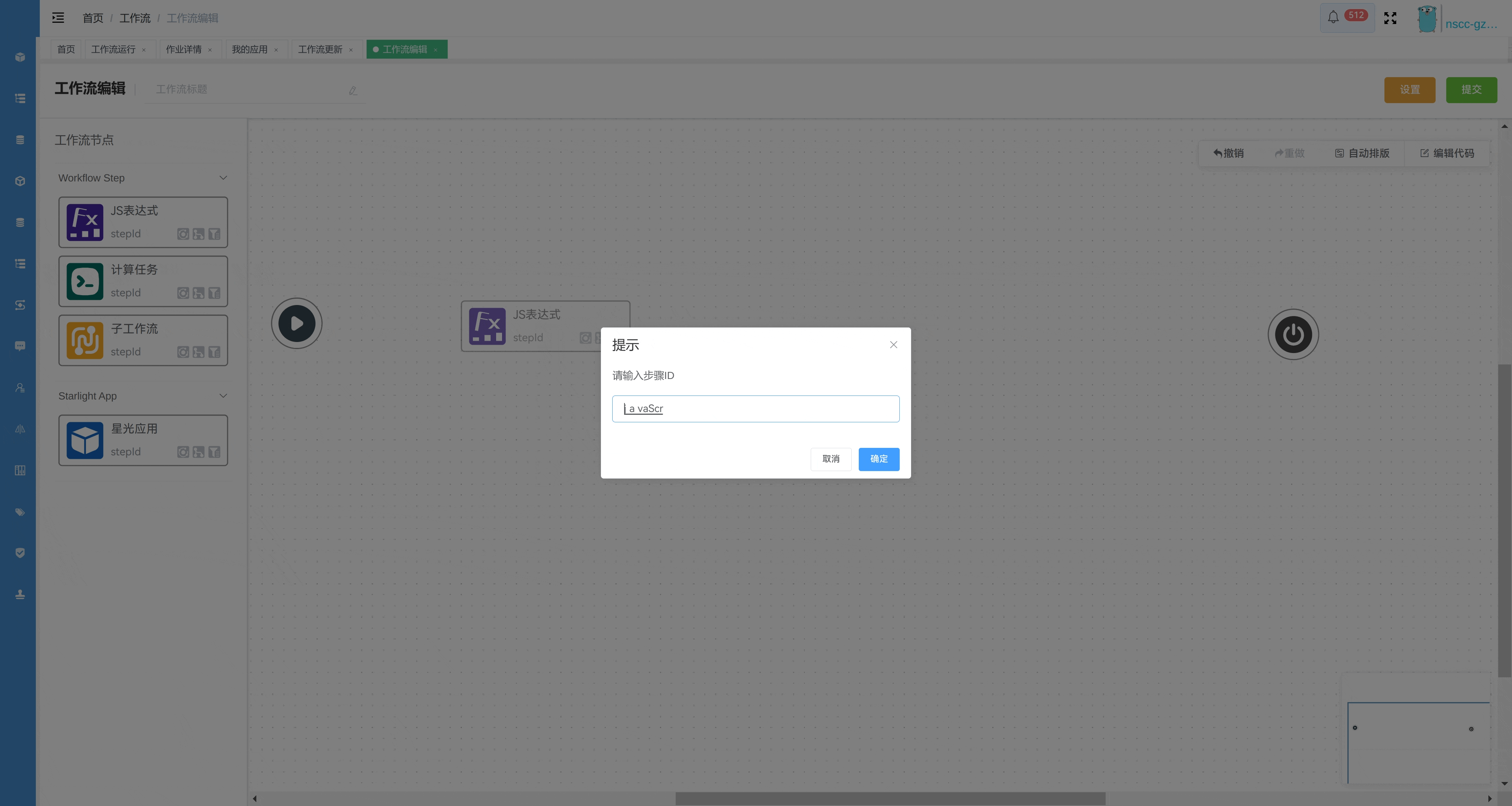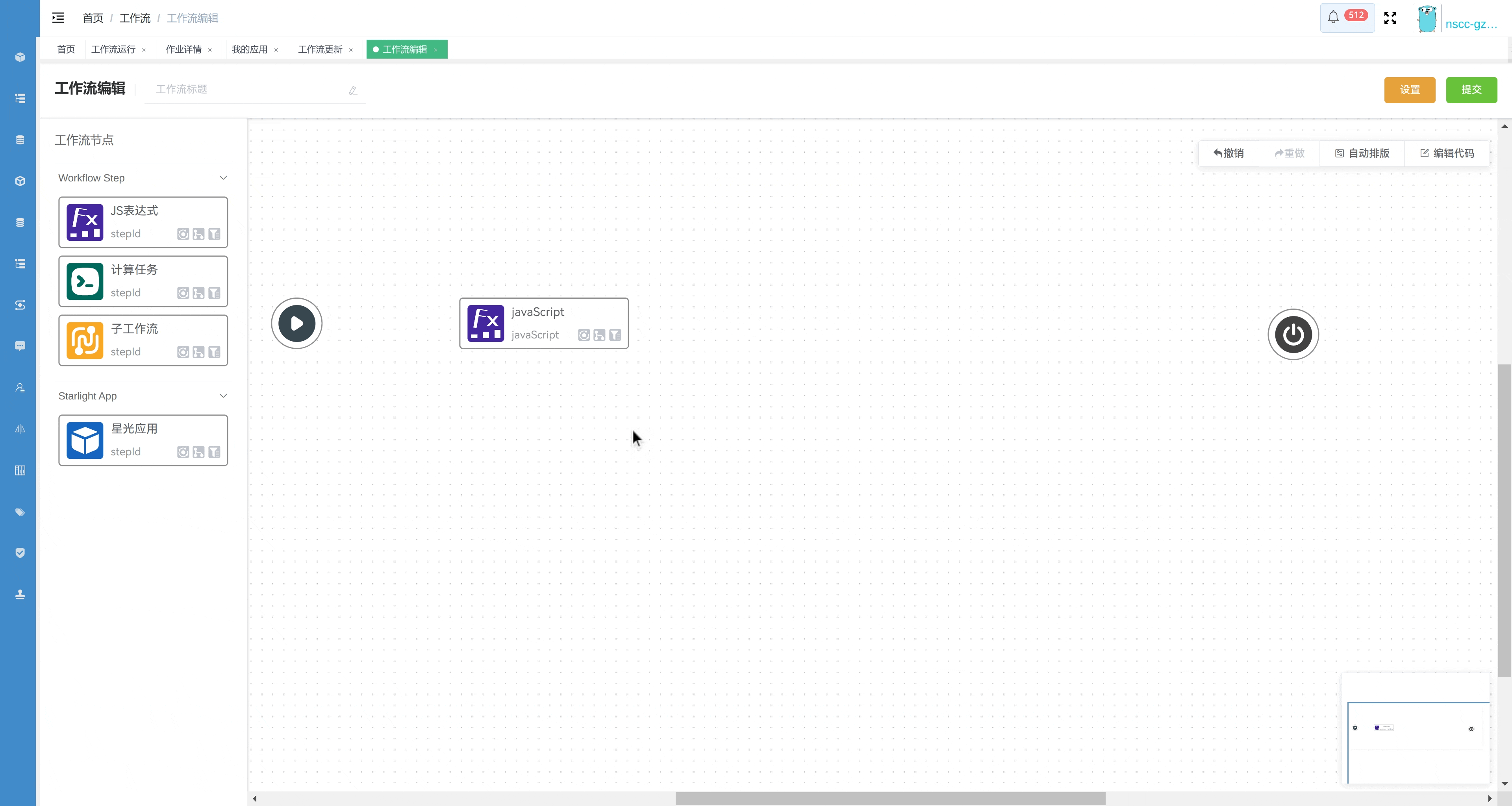
节点信息说明:
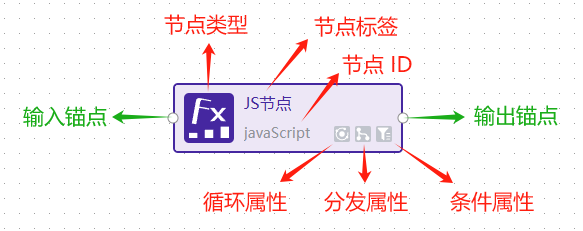
输入 / 输出锚点:
通过将一个节点 A 的输出锚点连接到节点 B 的输入锚点,表示 A 的输出将用于 B 的输入
将工作流的起始点连接到节点的输入锚点,表示该节点需要用户的输入
将节点的输出锚点连接到工作流的结束点,表示该节点的结果最终输出给用户
节点类型:
节点 ID 和标签:
节点的 ID 在当前工作流内应该是 唯一 的,且一经定义便不允许修改,用来标记和引用该节点,以便于在其它节点中引用该节点的输入、输出
节点标签用于为节点提供简要说明,区别于节点 ID ,并无重复性要求,且可随时修改
特殊属性:
双击节点可以打开 节点编辑 界面,进一步设置节点的属性。
开始 / 结束节点¶
工作流的整体输入和整体输出被抽象为两个特殊的节点。由于它们代表着工作流开始时需要的输入和工作流最终结束时输出的内容,因此称为 开始 节点和 结束 节点。

工作流就绪(流程可以运行)的前提是所有必要的输入参数都获取了具体的值,这些参数由用户在应用提交页通过填写参数表单中的对应项提供。
工作流应用会根据 工作流输入 自动推断产生应用提交页参数表单,如下图示例:
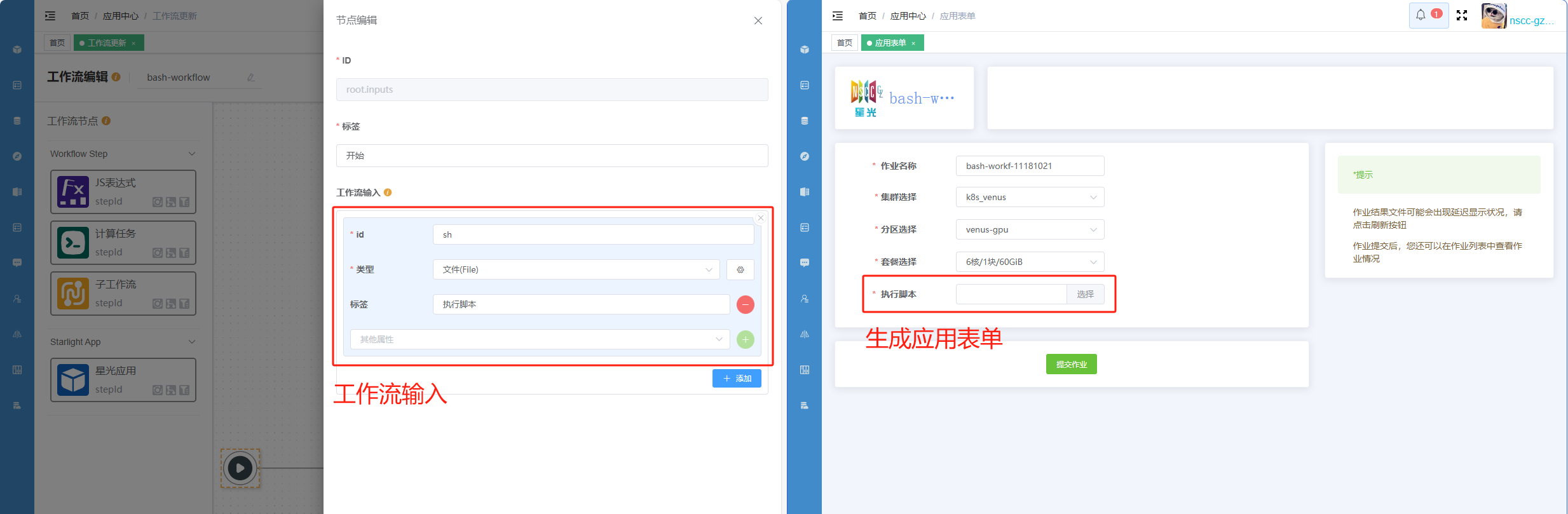
工作流输入输入参数的
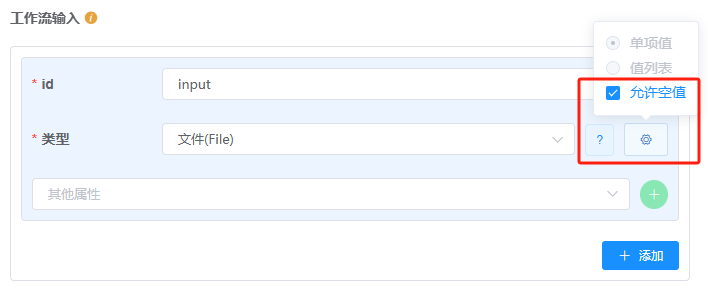
类型属性影响表单控件类型,并用于校验用户输入参数是否符合预期。常用类型有文件(File)、字符串(string)、 数值类型(int、float)等。并且可以通过在类型后加?表示该项参数允许空值(用户可以不指定该参数具体值,该参数如果没有设置默认值会被赋为null)。设置参数允许空值
设置输入参数的类型后,点击类型后出现的设置按钮,在出现的面板中勾选 “允许空值” 即可:
其他属性可以通过下拉菜单选择并点击右侧加号按钮添加,如下图所示: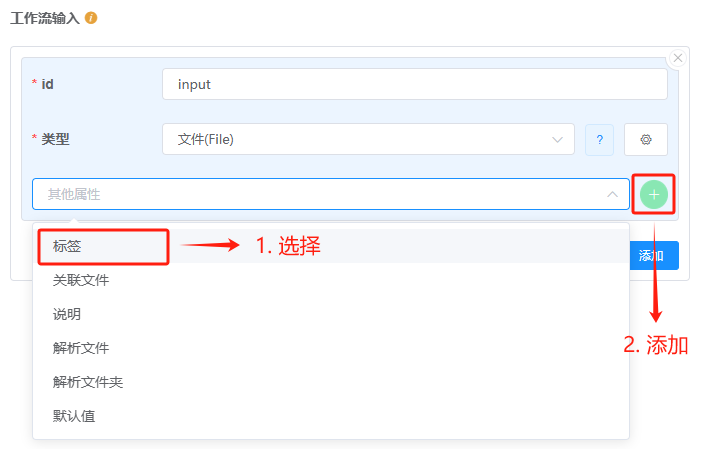
默认值属性可以在参数未被用户指定值时为参数赋默认值标签属性用于设置应用提交表单中该参数对应的前端控件的标签关联文件只有参数类型为File时生效,用于设置与主要文件相关的附加文件,以确保在使用主要文件时包含它们解析文件只有参数类型为File时生效,启用该属性后,在当前节点中可以使用.contents获取对应文件的内容 需要文件小于 64 kB解析文件夹只有参数类型为Directory时生效(当前版本暂不支持Directory类型参数,请等待后续更新),用于控制目录内容的加载方式,可以指定在运行时是否以及如何加载目录中的文件列表:不解析:不加载目录内容解析一层:仅加载目录的顶层内容,不递归加载子目录解析多层:递归加载目录及其所有子目录的内容
加载目录内容后,在当前节点中可以通过
listing字段访问这些文件列表
工作流成功运行结束后,将根据所设置的 工作流输出 产生相应的运行结果。这些输出来自于工作流各个步骤的输出参数,对于步骤中用户所关心的数据,可以将其关联至 工作流输出 以在工作流正常结束后查看。
工作流输出用于定义工作流任务正常结束后可以查看到的结果数据
工作流被嵌套使用时,可以作为其他节点的
输入源,详细信息请参考 输入输出关联
星光应用¶
已经编辑好的应用(包括工作流应用)可以直接用作工作流的一个节点。添加 星光应用 节点后,鼠标左键双击该节点进入 节点编辑, 在 执行过程 中设置该节点所对应的应用。该应用可以从 公共应用 (已发布至 应用列表 的应用 )或 我的应用 中选取。应用选取后会自动在 输入关联 、 输出 中填充该应用的输入、输出参数,根据实际需要再进一步设置所需的 输入关联 和 输出,详细信息请参考 输入输出关联。
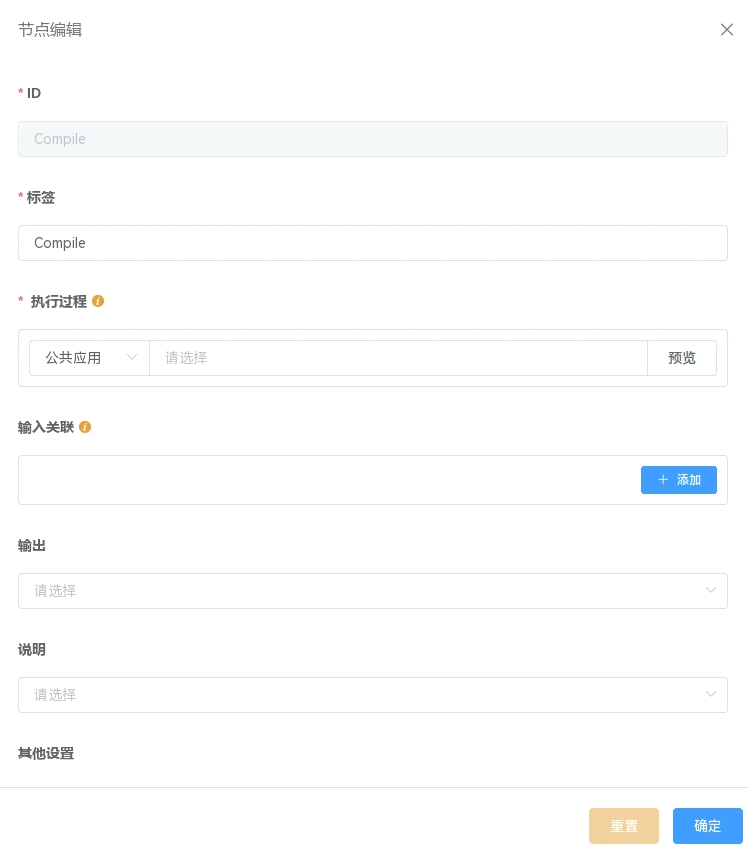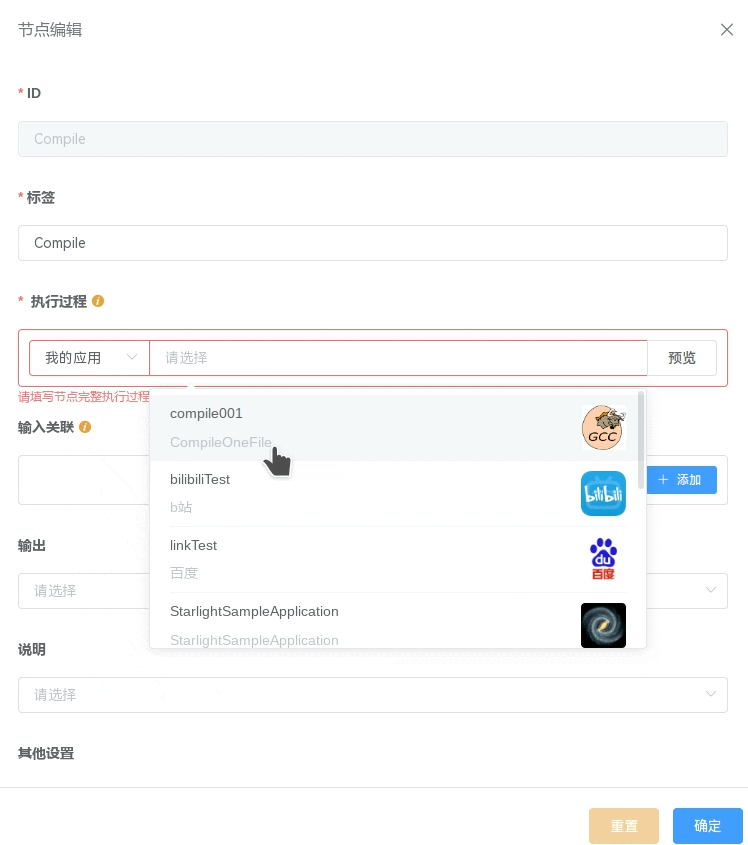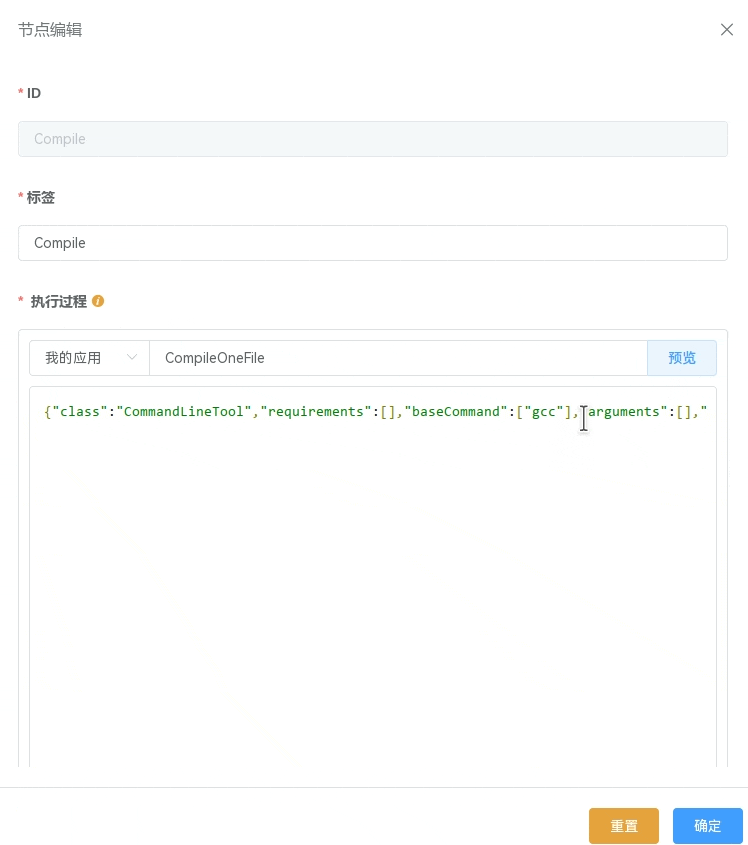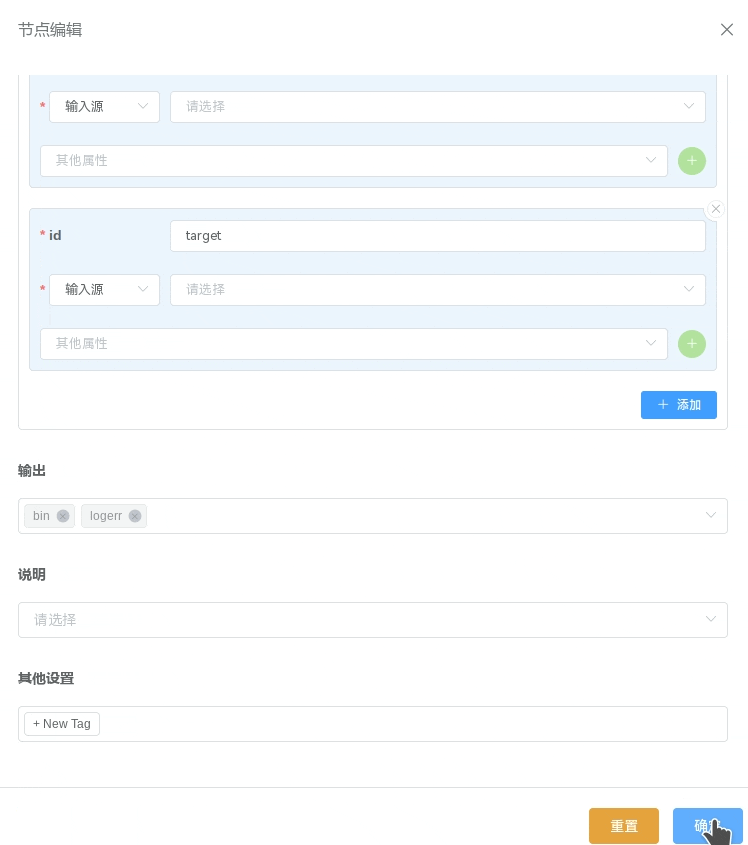
如果需要确认应用实际执行的内容,可以点击 “预览” 按钮查看当前所选应用的 CWL 文档。
备注
如果选择一个应用后,没有自动填写 输入关联 、 输出 等内容,或者预览文档时出现问题,可能是因为星光平台迭代过程中,尚未对您所选择的应用进行升级,无法用于工作流。您可以以该应用为模板 创建一个新应用,平台将自动进行升级。
计算任务¶
计算任务 支持工作流开发者自定义执行命令、输入输出参数等,以便应对平台现有应用无法满足需求的场景。
计算任务 的 执行命令 由一组字符串拼接,用来指定需要运行的程序或者参数。也可以是一个 JavaScript 表达式,用来从输入变量中取值,例如 “$(inputs.source.path)” (用于获取文件类型输入变量 “source” 的路径),甚至可以是一个匿名函数,将传入的参数做简单处理后再执行。
获取 计算任务 执行结果的方式:
如果计算的结果是打印到标准输出流的,可以设置一个类型为
stdout的输出变量,这样输出就会被重定向到指定的文件中;如果计算的结果是文件,可以使用通配符匹配的方式获取到某个(或某些)文件输出。
计算任务 节点的 执行过程 的定义和普通应用类似,一般需要定义以下几部分:
输入参数:与
工作流输入参数类似。所定义的参数的值可以在当前执行过程的其他部分的表达式中通过inputs.${id}进行访问执行命令:定义程序运行的命令,可以使用表达式
输出参数:常用的类型有:
stdout:即标准输出文件
stderr:即标准错误输出文件
File:可以通过添加
输出绑定属性(其他属性下拉选择并点击添加按钮), 选择通配符匹配设置当前参数关联到指定的文件
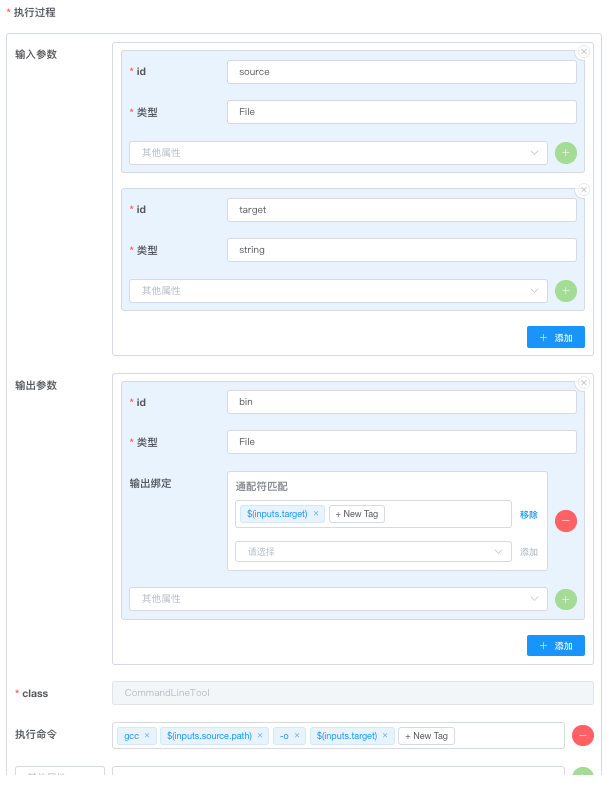
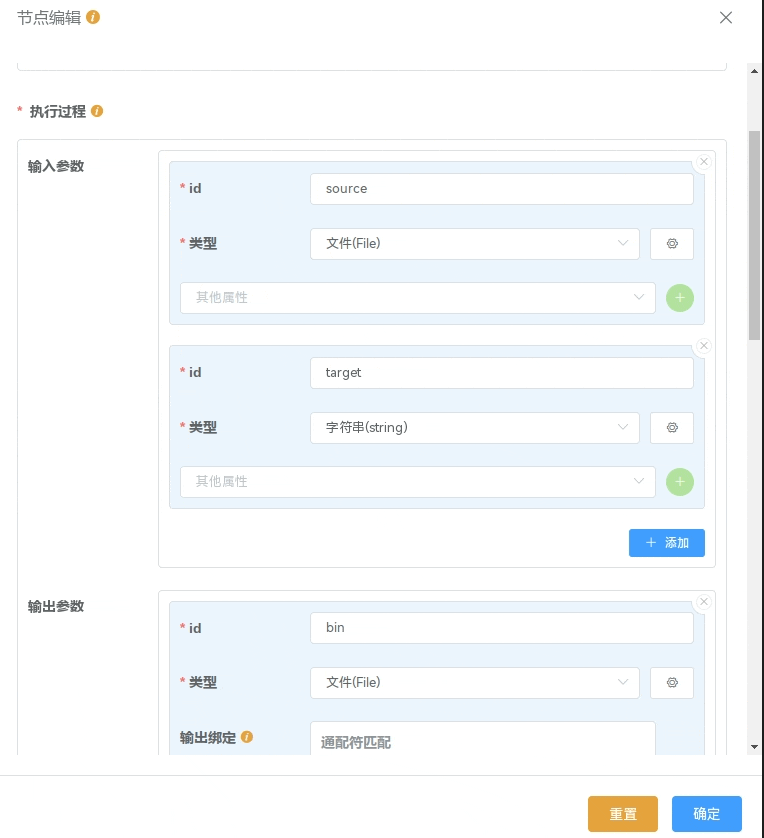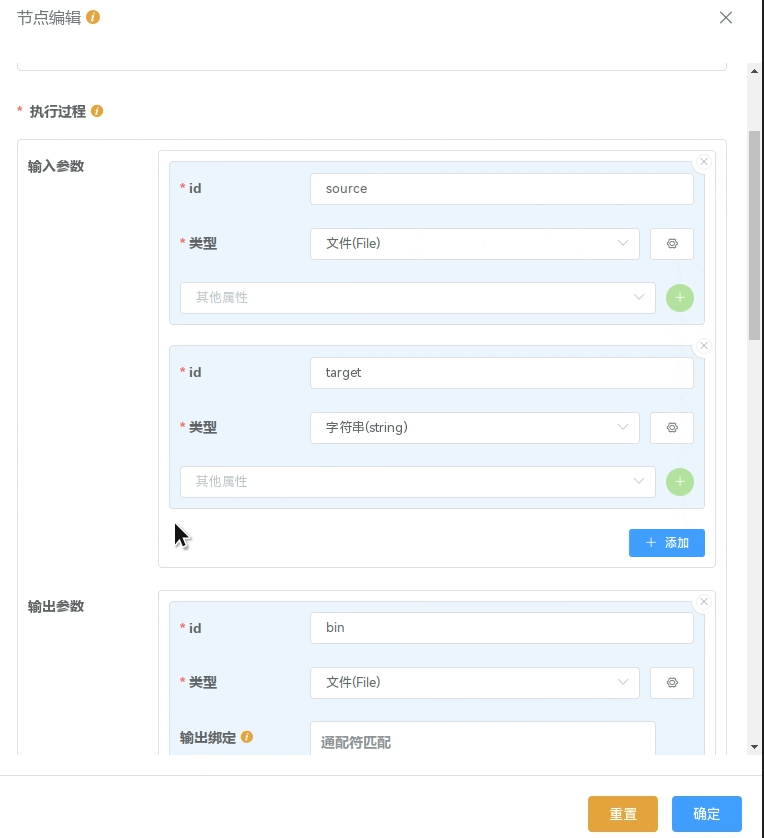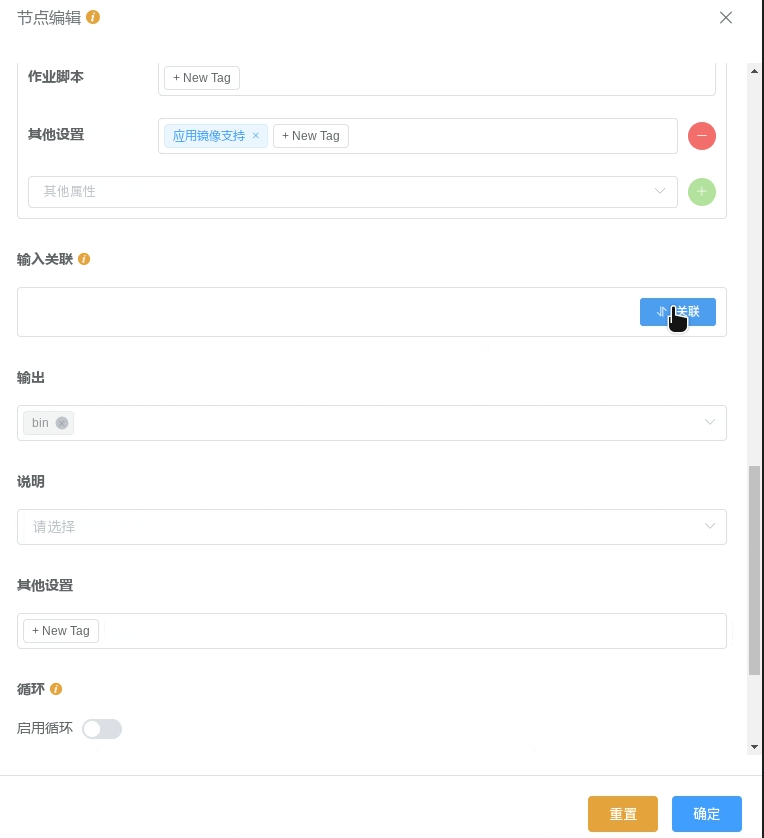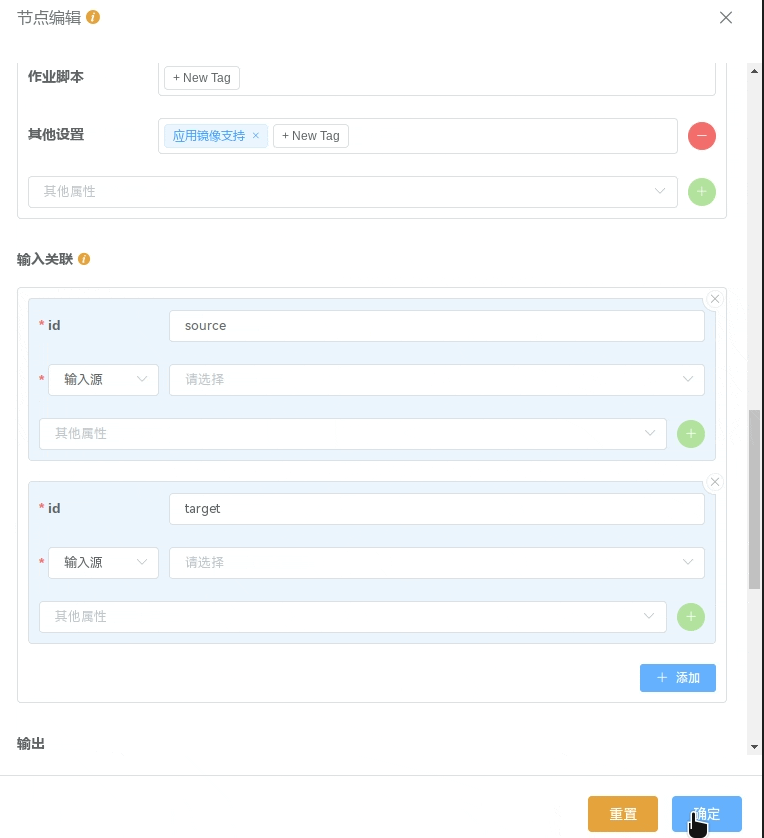
上图中定义了一个通过 gcc 编译单个文件的 执行过程:
输入参数:源文件(File) "source",目标文件名(string) "target"
执行命令:gcc $(inputs.source.path) -o $(inputs.target)
输出参数:"bin",根据
输出绑定/通配符匹配匹配到符合的文件
子工作流¶
为了充分利用分发、条件执行等功能,或者为了更好地组织工作流的层次结构,可以将多个步骤合并为一个 子工作流。
编辑 子工作流 的过程与编辑主工作流的操作是一致的。可以把 子工作流 当成一个独立的工作流来编辑,其内部的步骤 ID 是独立的,不会影响到 子工作流 之外的节点。如下图所示:
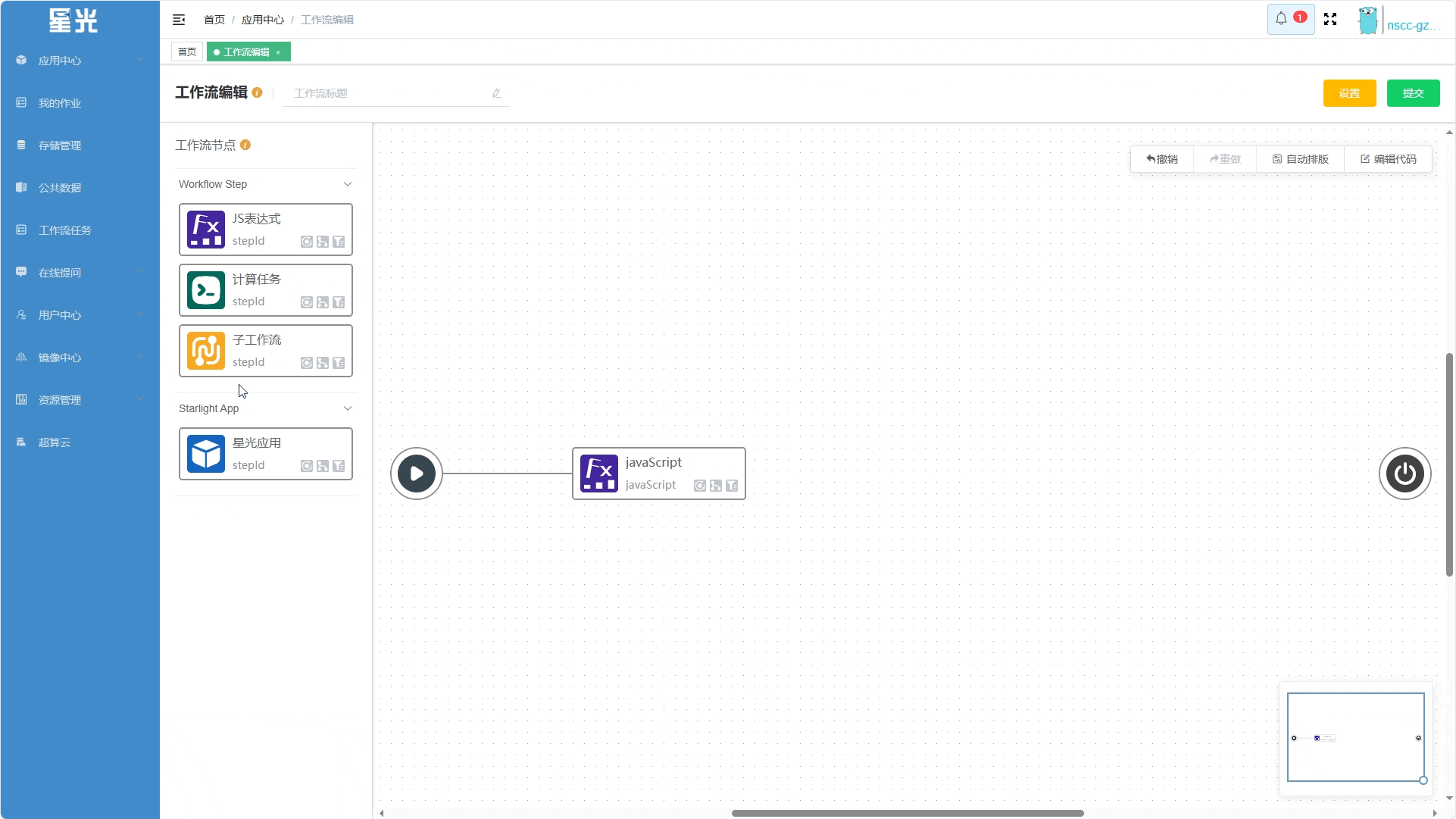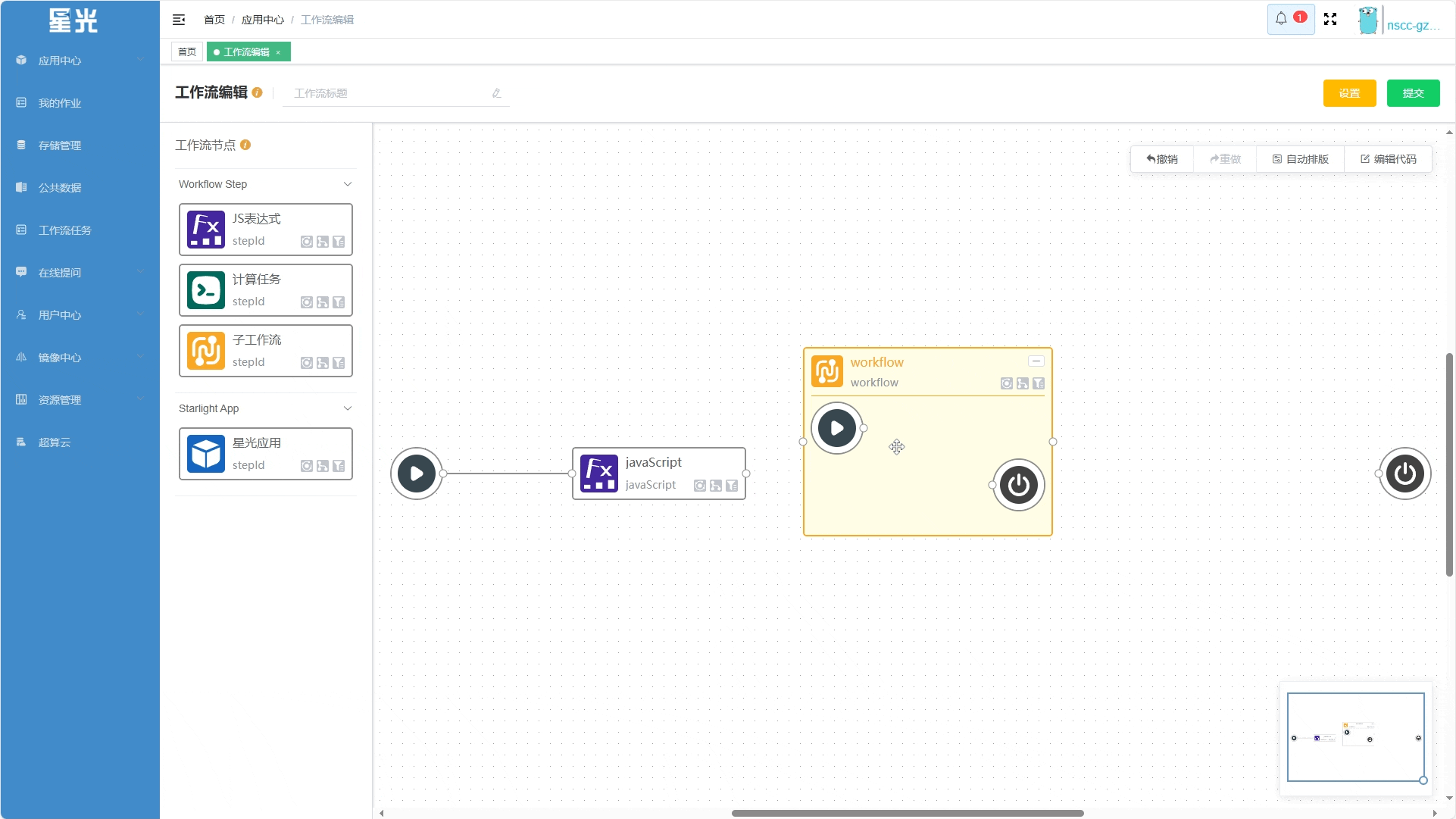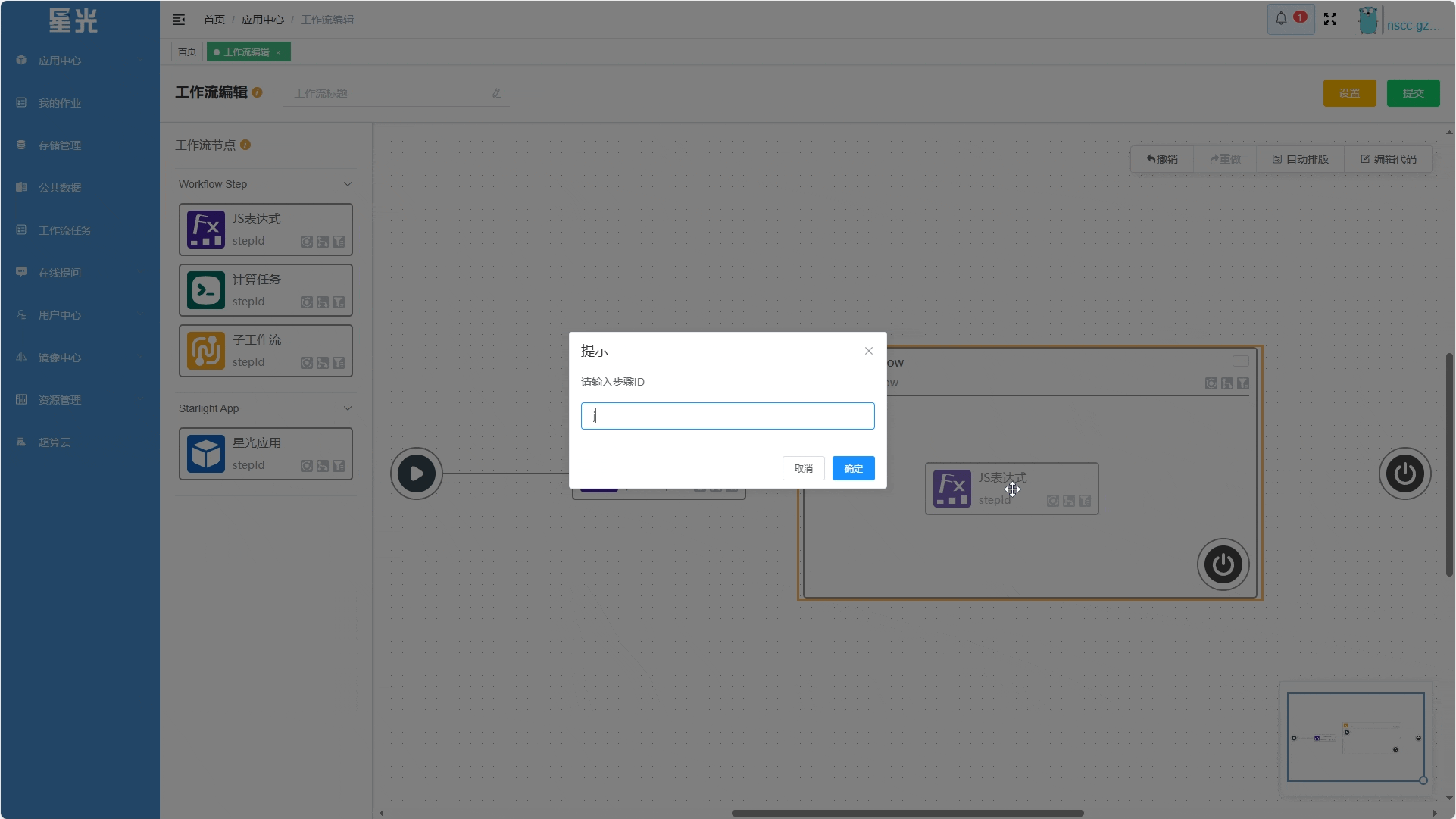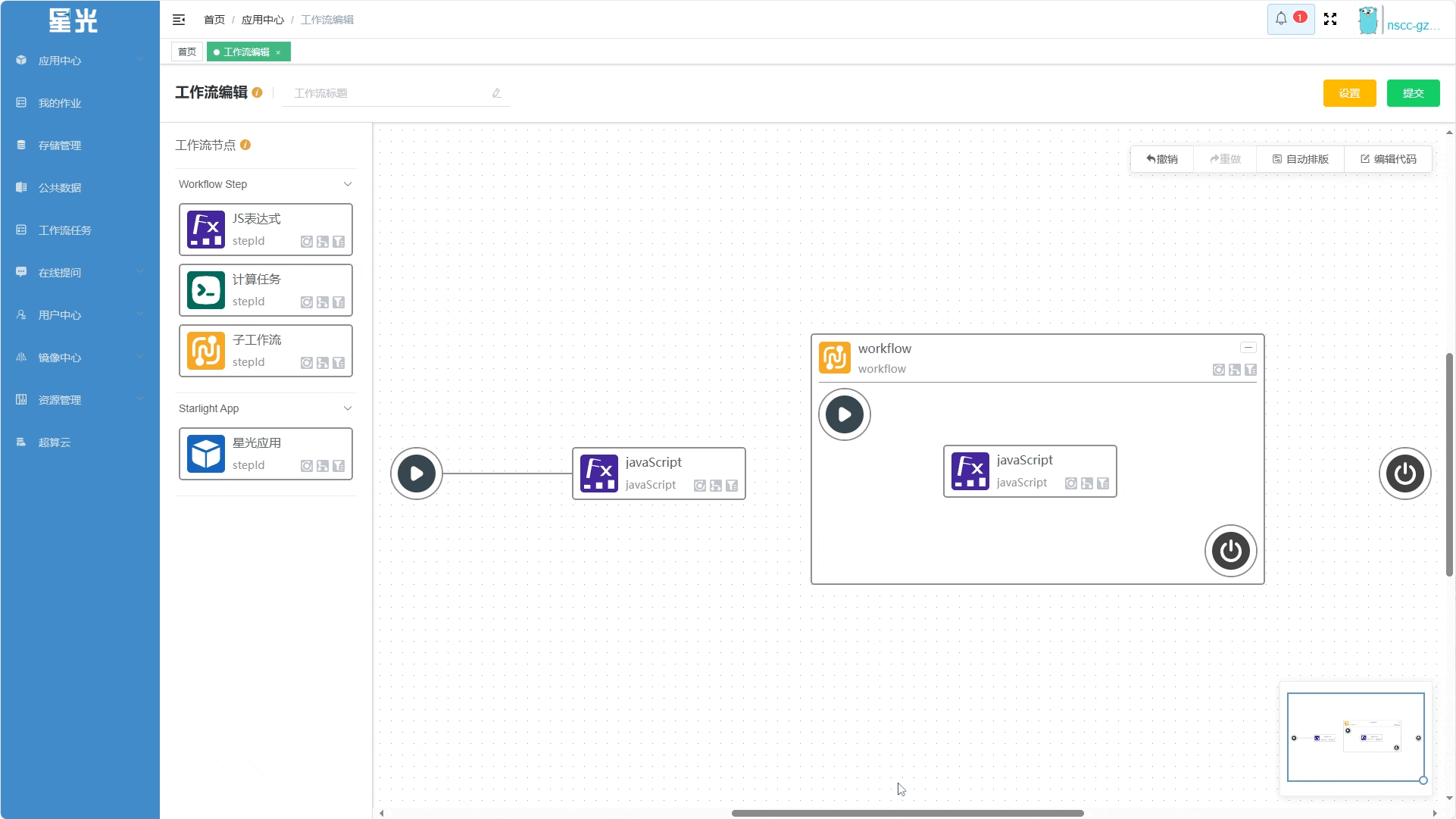
同时, 子工作流 本身也是主工作流的一个节点,节点内包含的子工作流即为该节点的 执行过程, 开始 节点/ 结束 节点便是其输入参数/输出参数的抽象。
作为一个工作流节点,其属性的编辑方式与其它节点相同。在完成子工作流的编辑后,鼠标左键双击 子工作流 节点即可打开 “节点编辑” 面板,对节点属性进行编辑:
设置所需的
输入关联和输出,详细信息请参考 输入输出关联使用分发、条件执行等属性
若需对子工作流进行更细致的调整,比如启用特定的文件解析功能,或是设定特定的环境变量,可以通过在
执行过程的 “其他属性” 中选择并添加 “其他设置” 来实现这一目的。备注
子工作流的 “其他设置” 与工作流 基本设置 中的 “其他设置” 类似,区别在于:子工作流的设置仅作用于子工作流本身,而工作流的设置则作用于整个工作流。
一些可能会使用 子工作流 节点的场景:
有一系列多个步骤都需要在指定条件下执行,此时如果每个步骤都设置该条件,比较繁琐且数据流动不好规划。此时可将这些步骤组织为一个
子工作流,为整体添加运行条件;有一系列多个步骤需要并发为多个任务,此时可以将多个步骤组织为
子工作流后再对其分发;有一个未编辑为工作流应用的工作流需要嵌入当前工作流(已编辑为工作流应用的工作流可直接通过
星光应用节点进行嵌入),此时使用子工作流,可以直接将该工作流嵌入,而不需要因为该工作流中存在与当前工作流中节点 ID 相同的节点而修改该工作流。
JS表达式¶
某步骤的输出数据可能需要经过前处理才能作为下一步骤的输入数据,例如将输出的多维数组扁平化,提取输出量的某些属性等等,在这种情况下,可以使用 JS表达式 来进行处理。
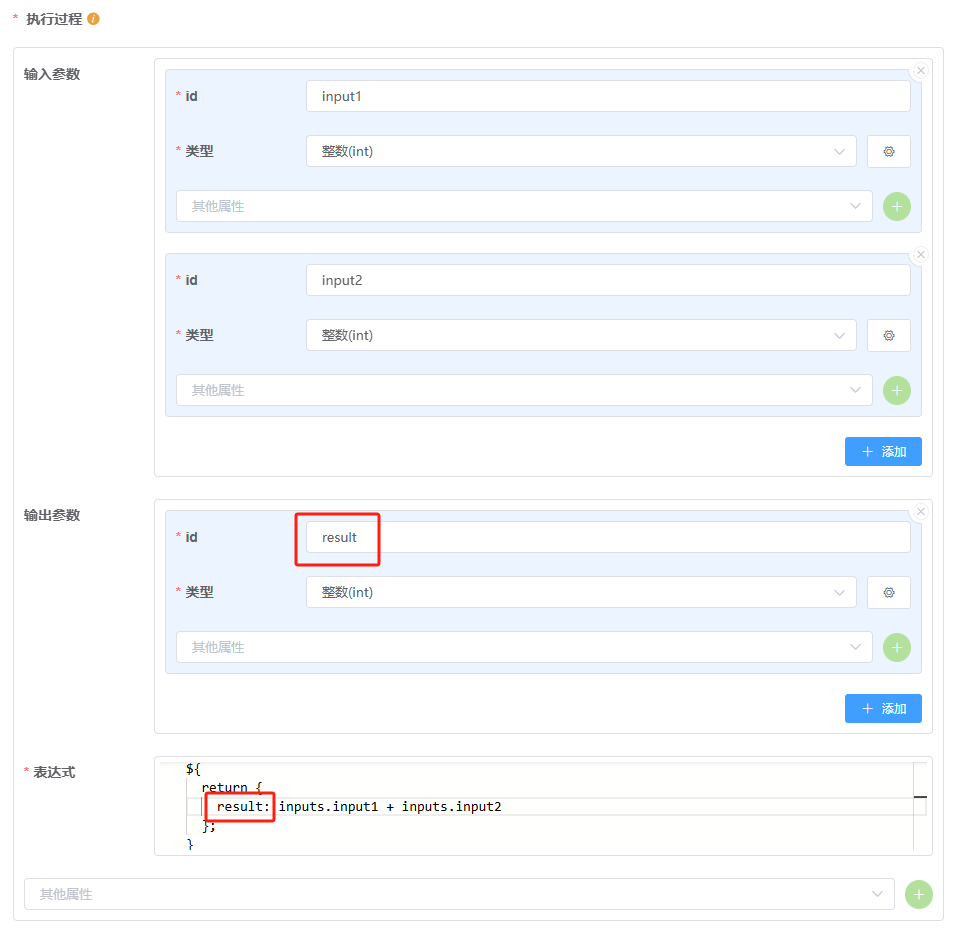
JS表达式 节点用于执行一段简单的 JS 表达式或者 JS 函数(使用 $() 包裹表达式,使用 ${} 包裹函数体),两者最终的结果都必须返回一个 对象,这个对象的键名需要与定义的输出参数 id 相匹配,以便正确绑定输出结果。
小心
运行这些 JS 代码的资源是有限制的,JS表达式 节点仅适合用于简单处理数据。如果数据需要使用大量内存或计算资源,请使用 计算任务 节点。
执行过程 的定义:
输入参数:与
工作流输入参数类似。所定义的参数的值可以在表达式部分通过inputs.${id}进行访问;输出参数:与工作流输出参数类似,定义需要传递给其他节点的结果数据;
表达式:需要计算的 JS 表达式。表达式的计算结果应该是一个 JS 对象,对应输出参数中的定义。如下图所示:
备注
表达式具体细节请参阅 表达式
输入输出关联¶
输入输出关联的设置:
通过在不同节点的输入、输出锚点间连线确定节点间存在数据关联(参考 新建星光应用节点(Step1 Compile 编译)
在
节点编辑中进一步设置输入关联来明确该节点具体的输入参数与其它节点的输出的关联通过设置
输出来明确将该节点执行过程的某些输出参数对其它节点暴露输入关联:在
执行过程中所定义的输入参数,在输入关联中均需拥有相同id的对应项,以设置该参数的输入源;分发、条件执行等功能所用到的参数,也需要在
输入关联中设置相应参数的输入源;输入源可选择其他节点的输出项或所属工作流的输入参数项;输入源可以选择多项,但每一项必须是兼容类型。默认情况下会将所有输入源合并为一个嵌套数组,并全部返回;用户可通过输入组合方法、多值组合方法自定义参数组合方法。自定义输入源组合方法
假设您将
输入源设置为三个输入文件: file1、file2 和 file3设置
输入组合方法设置值为 “嵌套” 时结果如下:
[[file1], [file2], [file3]]设置值为 “扁平” 时结果如下:
[file1, file2, file3] # 如果 file1 是一个数组,例如 [file1a, file1b],而 file2 和 file3 是单个文件,那么 input_files 将是: [file1a, file1b, file2, file3]
设置
多值组合方法设置值为 “第一个非空值”
从经过
输入组合方法处理后的数据中选择第一个非空值并返回,若所有值均为空值,则报错。设置值为 “唯一非空值”
若经过
输入组合方法处理后的数据中,有且仅有一个非空值,则选择并返回,否则则报错。设置值为 “所有非空值”
从经过
输入组合方法处理后的数据中选择所有非空值,作为一个数组返回;若所有值均为空值,则返回一个空数组。
输出:从
执行过程的输出参数列表中选择需要提供给其他节点使用的项。
当您完成一个工作流节点的 执行过程 的编辑后,对于已在 执行过程 中定义的输入参数,只需点击 输入关联 编辑框中的 “关联” 按钮,即可自动创建相应的 输入关联``(对于 ``星光应用 节点,在您完成应用选择时则自动创建相应的 输入关联,无需主动触发),只需为这些关联设置数据源即可完成配置。
如果不需要这些关联,可以随时手动将它们删除。
特殊流程控制¶
条件执行¶
设置 执行条件 表达式,可以控制就绪的节点是否需要执行。表达式必须返回 布尔值。
备注
执行条件 表达式的编写请参考 表达式
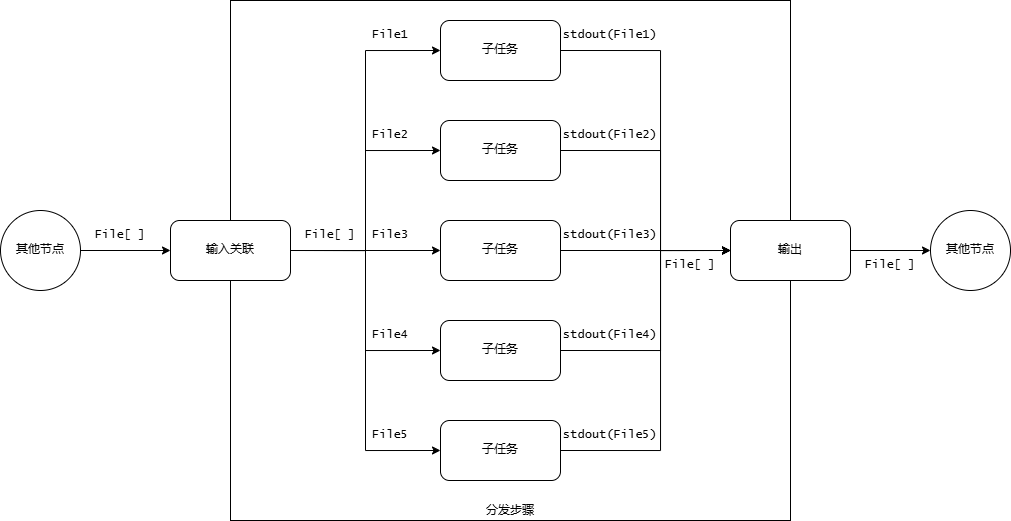
分发执行¶
通过定义一组(或多组)数据输入,工作流执行器可以将它们拆分成多个任务的输入,并且并发地执行这些任务。
例如,对于一个计算单个文件行数的节点,输入一个包含 5 个文件的数组,将这个数组指定为 分发输入,工作流执行器就会创建 5 个计算行数的任务,并且同时执行它们,最后将这 5 个子任务的结果汇总作为该节点的输出。上述过程的数据流动如图:
定义执行过程¶
对于需要分发执行的节点,所定义的执行过程实际上是每个 子任务 的执行过程。因此在上述的计算行数的例子中, 执行过程 是输入单个文件计算行数并输出单个结果。
run:
class: CommandLineTool
arguments:
- wc
- "-l"
- $(inputs.FileToCount.path)
inputs:
- id: FileToCount
type: File
outputs:
- id: Line
type: stdout
在星光的可视化编辑中,上述文档如图:
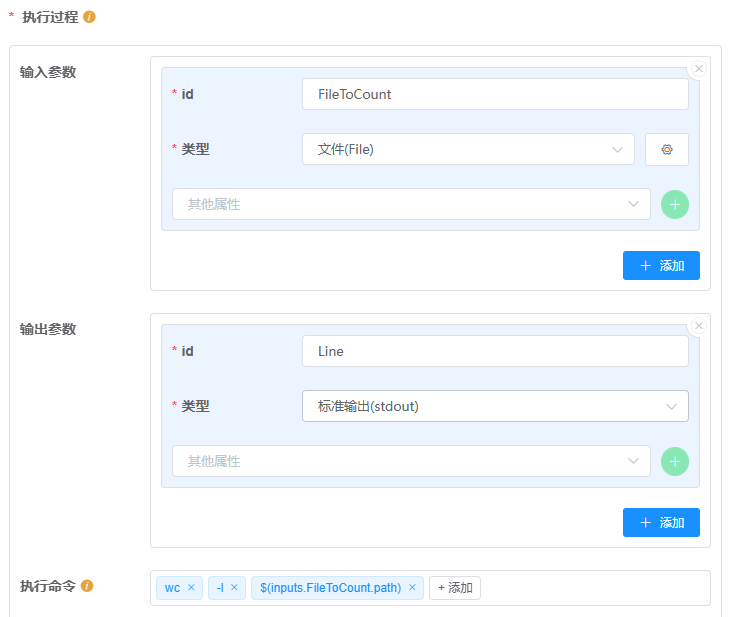
定义输入输出关联¶
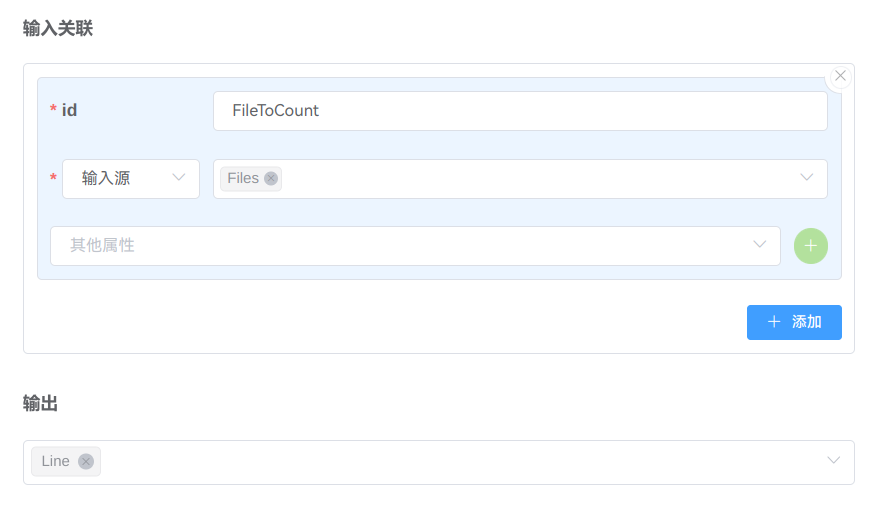
输入关联分发执行的节点中需要用于分发的节点输入为该节点
运行过程中所定义的输入参数的集合(数组)该节点
输入参数在输入关联中所设置的输入源的类型必须是输入参数类型的数组
输出分发执行的节点的每个
输出为该节点执行过程中所定义的对应输出参数的集合(数组)其它节点若要使用分发执行的节点的输出,其
输入参数的类型需为分发执行节点的输出参数类型的数组
在本例中,需要分发执行的行数统计节点的输入是一个文件数组、输出也是一个文件数组。该节点的输入来源于 开始 节点,输出至 结束 节点。为此,需要将 工作流输入、 工作流输出 设置为数组:
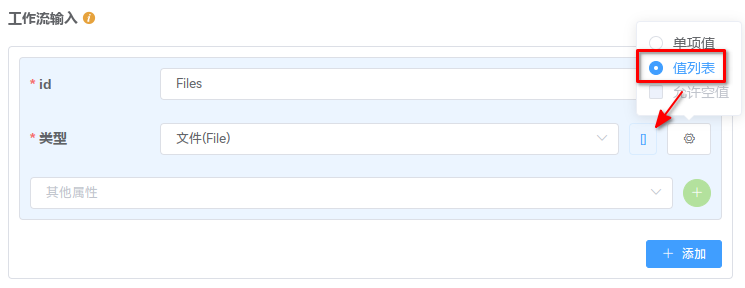
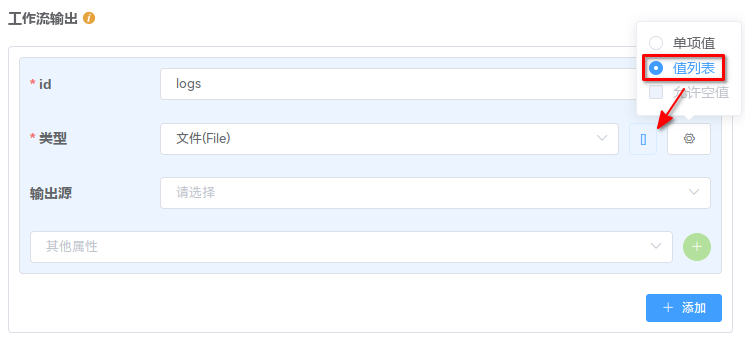
备注
注意红框中的 “值列表” 选项,这表示变量的类型是一个值列表;勾选该选项之后,会自动出现一个 [] 符号以做提示。
这样,就可以把前面定义的分发节点与 开始 、 结束 节点关联起来了:
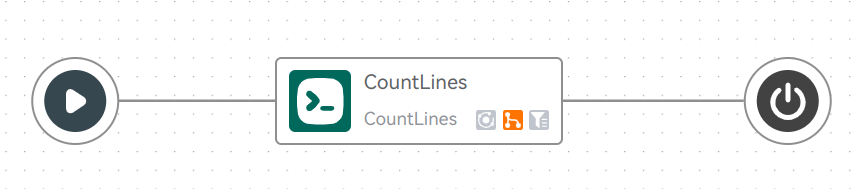
备注
上述的过程对应的(简化的)CWL文档如下:
class: Workflow
inputs:
- id: Files
type: File[]
outputs:
- id: Lines
type: File[]
outputSource: CountLines/Line
steps:
CountLines:
in:
- id: FileToCount
source: Files
out:
- Line
run:
class: CommandLineTool
arguments:
- wc
- "-l"
- $(inputs.FileToCount.path)
inputs:
- id: FileToCount
type: File
outputs:
- id: Line
type: stdout
分发输入¶
分发输入( Scatter )用于指定节点中需要分发执行的输入,支持分发多个节点输入。当节点的 输入绑定 设置完成后,对于需要分发的节点输入,即可于 分发输入 中进行设置并分发执行。
在本例中,需要分发的仅有一个参数 "FileToCount",在节点的 分发输入 中选择该参数即可。

备注
假设存在某个节点,其 执行过程 定义了两个 输入参数 A (int) 和 B (File),以及两个 输出参数 C (int) 和 D (string)。若指定 B 为需要分发的输入,那么 输入绑定 中, A 的 输入源 需为 int 类型, B 的 输入源 则需为 File[] 类型,而经过分发执行后, 输出 则为 C (int[]) 和 D (string[])。
分发方法¶
分发方法( scatterMethod )用于在指定多个节点输入进行分发时,决定如何产生输入参数的集合以分配给子任务,以及所有子任务输出参数的层次结构:
点乘
dotproduct将每个分发输入按顺序一一对应地组合在一起,每个子任务都从所有数组中取出一个元素进行分发。任务的结果也组织为一个一维数组。这个方法要求所有被分发的输入参数必须具有相同的长度,如果长度不一致,工作流将会报错。
叉乘
nested_crossproduct计算分发输入的笛卡尔积,按照计算结果产生子任务。任务的结果也根据笛卡尔积的形式组织为一个多维数组。
叉乘并扁平
flat_crossproduct与上面叉乘相似,但是不保持层次结构,将任务的结果扁平化为一个一维数组。
假设有 2 个参数 A、 B 需要分发, C 不需要分发:
inputs:
A: ["a1", "a2", "a3"]
B: ["b1", "b2", "b3"]
C: "c"
dotproduct:
1: {A:"a1", B:"b1", C:"c"}
2: {A:"a2", B:"b2", C:"c"}
3: {A:"a3", B:"b3", C:"c"}
nested_crossproduct:
1:
1-1: {A:"a1", B:"b1", C:"c"}
1-2: {A:"a1", B:"b2", C:"c"}
1-3: {A:"a1", B:"b3", C:"c"}
2:
2-1: {A:"a2", B:"b1", C:"c"}
2-2: {A:"a2", B:"b2", C:"c"}
2-3: {A:"a2", B:"b3", C:"c"}
3:
3-1: {A:"a3", B:"b1", C:"c"}
3-2: {A:"a3", B:"b2", C:"c"}
3-3: {A:"a3", B:"b3", C:"c"}
flat_crossproduct:
1-1: {A:"a1", B:"b1", C:"c"}
1-2: {A:"a1", B:"b2", C:"c"}
1-3: {A:"a1", B:"b3", C:"c"}
2-1: {A:"a2", B:"b1", C:"c"}
2-2: {A:"a2", B:"b2", C:"c"}
2-3: {A:"a2", B:"b3", C:"c"}
3-1: {A:"a3", B:"b1", C:"c"}
3-2: {A:"a3", B:"b2", C:"c"}
3-3: {A:"a3", B:"b3", C:"c"}
与条件执行同时使用¶
分发执行还可以同时与条件执行一起使用,此时,执行器会针对 每一个 子任务 分别 做一次条件表达式计算,以确定是否跳过这个子任。换句话说,在 执行条件 中设置的条件控制的是每个子任务的运行与否,而非整个步骤的运行与否。
为了保证仍旧能通过结果数组元素序号判断某个结果属于哪个子任务,被跳过的子任务的结果会用 null 来占位。
我们依旧使用上面的例子来演示:
inputs:
A: ["a1", "a2", "a3"]
B: ["b1", "b2", "b3"]
C: "c"
when: ${inputs.A !== "a2"}
scatter: [A, B]
scatterMethod: flat_crossproduct
# 其结果为
1-1: {A:"a1", B:"b1", C:"c"}
1-2: {A:"a1", B:"b2", C:"c"}
1-3: {A:"a1", B:"b3", C:"c"}
2-1: null
2-2: null
2-3: null
3-1: {A:"a3", B:"b1", C:"c"}
3-2: {A:"a3", B:"b2", C:"c"}
3-3: {A:"a3", B:"b3", C:"c"}
若需去除上面结果中的 null ,可在 “绑定该结果为输入源的节点输入” / “绑定该结果为输出源的工作流输出” 中使用多值组合方法( pickValue )对空值进行过滤,可选值有:
第一个非空值
first_non_null取列表第一级的第一个非空值,若不存在非空值时报错,例如:
[null, x, null, y] -> x [null, [null], null, y] -> [null] [null, null, null] -> Runtime Error唯一非空值
the_only_non_null取列表第一级的唯一一个非空值,若有多个非空值时报错,例如:
[null, x, null] -> x [null, x, null, y] -> Runtime Error [null, [null], null] -> [null] [null, null, null] -> Runtime Error所有非空值
all_non_null取列表第一级的所有非空值,例如:
[null, x, null] -> [x] [x, null, y] -> [x, y] [null, [x], [null]] -> [[x], [null]] [null, null, null] -> []
循环执行¶
使得某个节点重复执行,直至满足条件。
使用该功能,可以充分简化计算流程中多次重复的部分,避免重复编写相似的节点;或是实现深度学习一类的优化计算/训练的需求,而不需要自行编写重复执行的脚本。
简单循环¶
简单循环指不打开 保留过程数据 功能,此时输出的类型将与未启用循环功能时保持一致。
我们按照如下的流程编辑一个包含简单循环节点的工作流:
正常编辑工作流,保证各节点间输入输出匹配
编辑需要启用循环的节点,打开
启用循环开关保持 “保留过程数据” 开关是关闭的
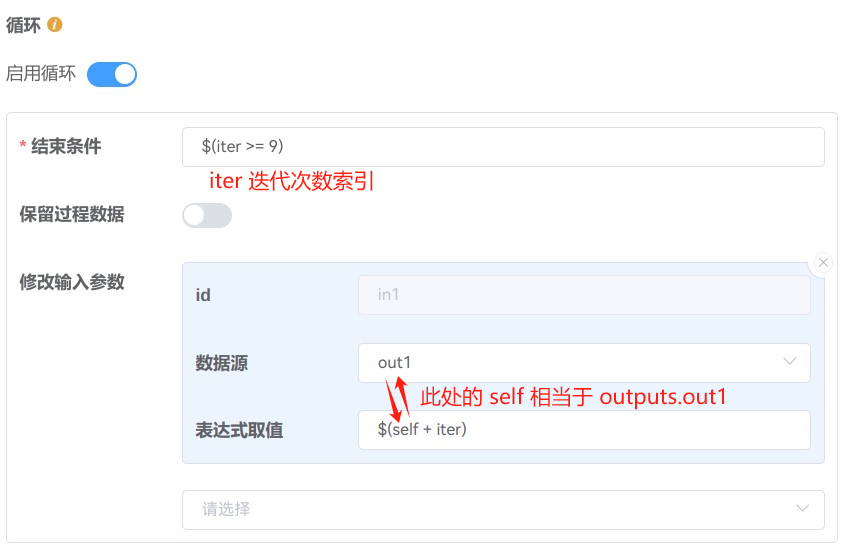
定义一个 “结束条件” 表达式,使其仅在需要结束循环时计算结果为
true。例如需要在第 10 次循环迭代后退出(此时对应的迭代次数索引iter为9),则表达式为$(iter >= 9)为了在两次迭代之间更新输入的值,还需要定义
修改输入参数项选择一个需要修改的输入
如果希望将其直接替换为某个输出,在
数据源处选择对应的输出即可如果有另外的逻辑需求,可以使用
表达式取值计算输入参数的新值(此时如果定义了数据源,可以使用变量self访问,而不需要通过outputs进行引用)
经过上述操作后,就完成了一个带有简单循环步骤的工作流。在运行它时,与分发步骤类似,也可以分别查看每一步的输入输出、对应作业等信息。
启用历史的循环¶
对于启用历史记录的循环节点,其输出包含了所有迭代任务的输出,因此与分发步骤类似,输出的类型会自动转换为数组。
需要调整关联该节点输出的其它节点的 输入参数 类型:
编辑循环节点,打开
保留过程数据开关此时,在
结束条件和表达式取值的表达式中,可以使用history变量来访问历史数据,例如:$(history[iter-1].inputs.A) # 访问前一次迭代的输入A $(history[0].outputs.B) # 访问第一次迭代的输出B现在该节点的实际输出已经变为一个数组,所以需要修改所有接收该节点数据的节点的
输入参数数据类型。假设循环节点直接输出到工作流的
结束节点,且循环节点的执行过程(亦即每个迭代的执行过程)输出为单个整数int,那么就需要修改工作流输出的数据类型为整数数组int[]。
当循环与分发或条件执行一起执行时……
循环功能与分发功能在语义上有重叠, 无法一起使用。
循环功能可以和执行条件一起使用。此时, 执行条件会先被计算,然后再执行循环节点。在循环节点中,各个迭代任务执行时不再计算执行条件。
备注
循环是一个星光基于 CWL 语法发展的新特性。如果您需要了解实现的细节,可以参考 循环功能实现。
工作流设置¶
基本设置¶
定义工作流应用的基本信息。
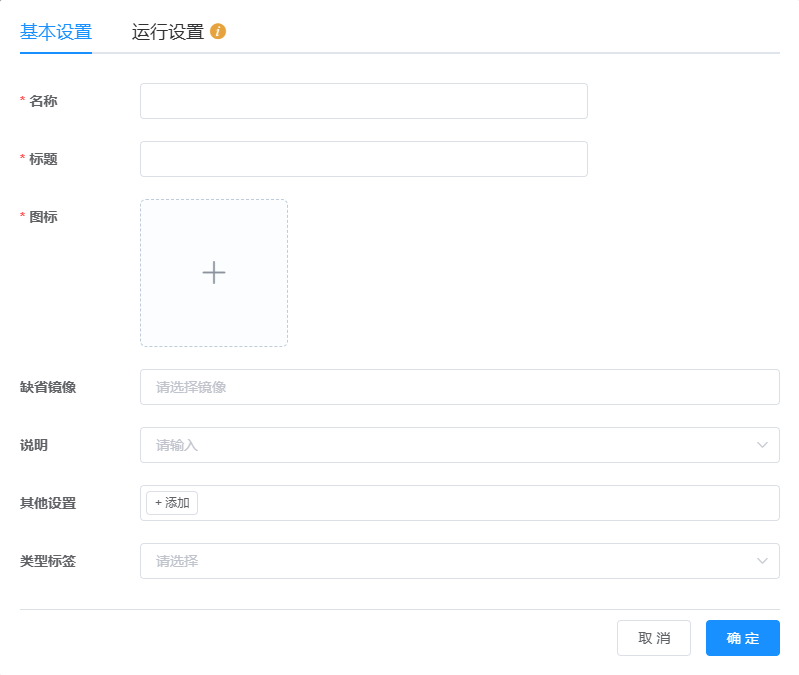
名称:即应用名称,应用在数据库中的名称,必须是唯一的,若重复,则无法提交
标题:即应用标题,展示给用户的标题
图标:即应用图标,展示用图标,具体效果请见 应用卡片
缺省镜像:工作流应用的镜像缺省值,若工作流中的
计算任务节点与星光应用节点未设置镜像,则以该缺省值为默认镜像说明:即应用描述,简短的描述,用于介绍应用的基本信息,背景、用途等(以字符串数组的形式保存,展示时拼接为字符串)
其他设置:用于设置工作流的扩展功能支持
表达式插值支持
InlineJavasciptRequirement解析文件夹支持
LoadListingRequirement应用镜像支持
DockerRequirement初始化工作目录
InitialWorkDirRequirement环境变量支持
EnvVarRequirementshell命令支持
ShellCommandRequirement子工作流支持
SubworkflowFeatureRequirement分发输入支持
ScatterFeatureRequirement多输入链接支持
MultipleInputFeatureRequirement表达式取值支持
StepInputExpressionRequirement
类型标签:将应用与一个或多个类型关联起来,方便用户在
应用列表页分类查看、检索
运行设置¶
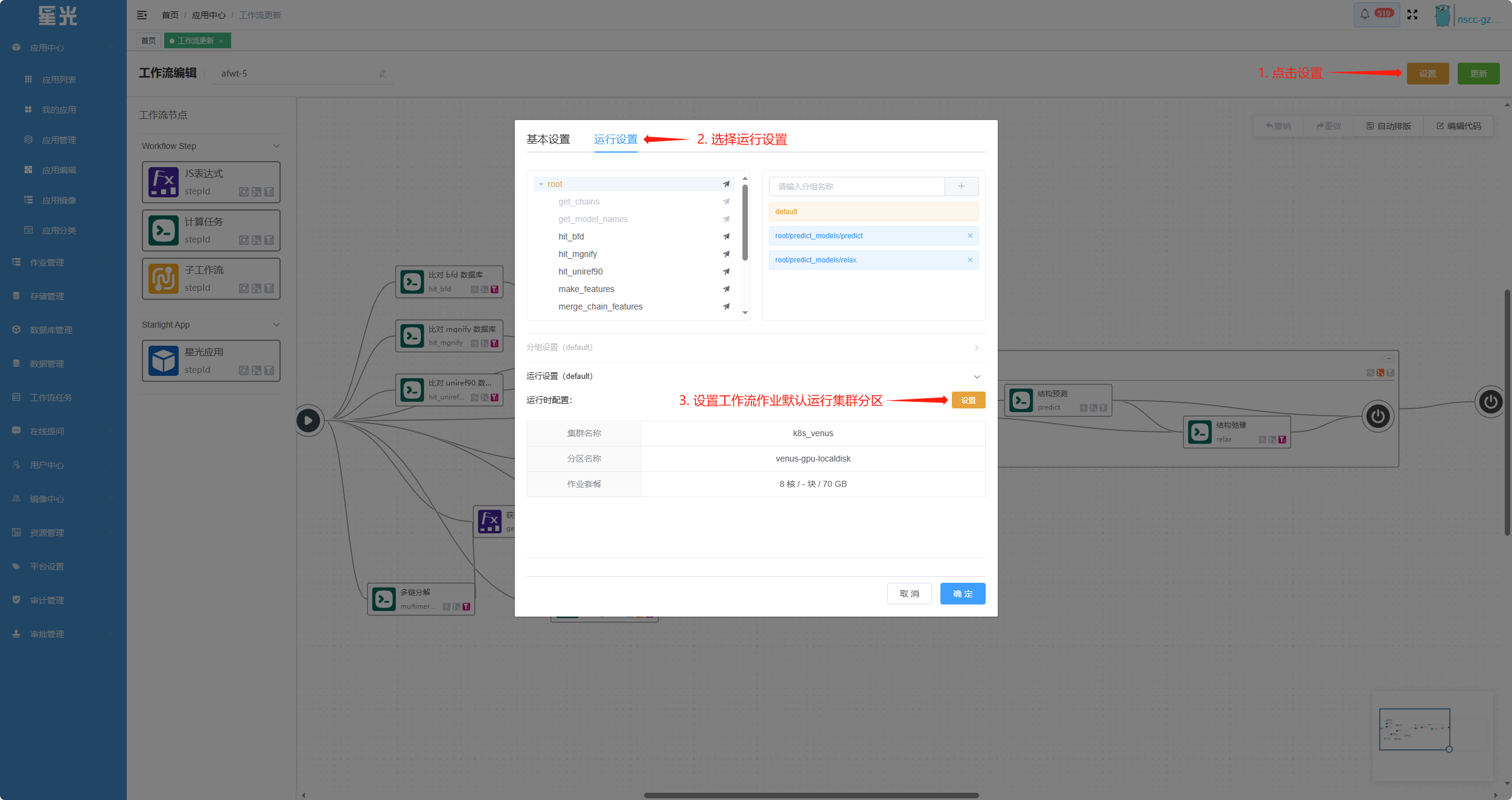
定义工作流中的每个节点的资源需求,如在某个特定的集群分区运行、使用特定的资源等。
界面说明¶
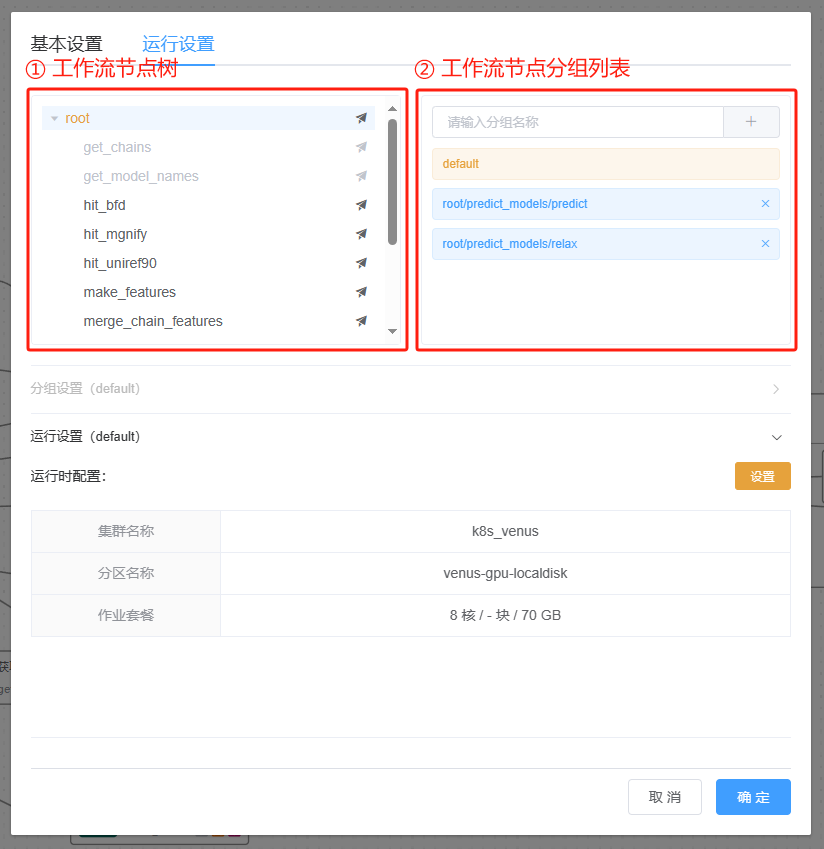
工作流节点树
根据工作流各节点之间的结构关系所生成的节点树
其中 root 节点为工作流的根节点,用于设置工作流运行的 “默认设置”——
default,且必须设置。当存在未进行运行设置的节点时,该节点则按照default设置运行当节点类型为
JS 表达式/子工作流时,无需进行运行设置,故该节点处于不可设置状态当节点类型为
计算任务/星光应用时,可以对该节点进行独立的运行设置
工作流运行设置颜色图例
 默认设置
默认设置 节点设置
节点设置 分组设置
分组设置
节点设置¶
针对单个节点,设置其运行资源需求:
指定需要设置的节点
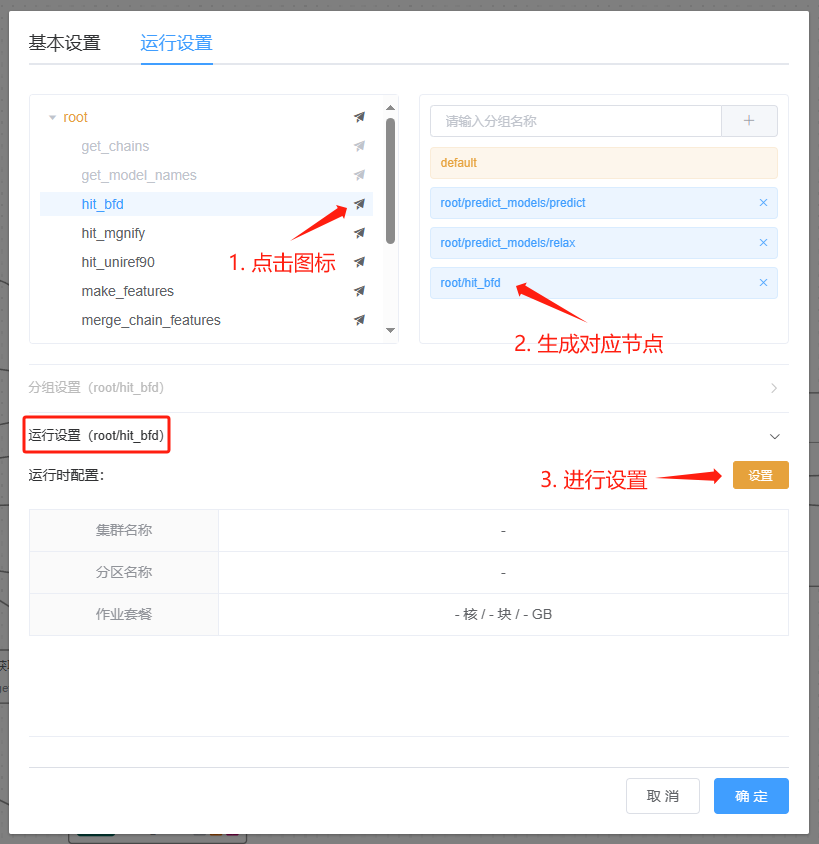
对节点进行 运行时配置。
分组设置¶
对若干资源需求相同的节点建立分组,设置其运行资源需求:
添加分组并对节点进行分组设置
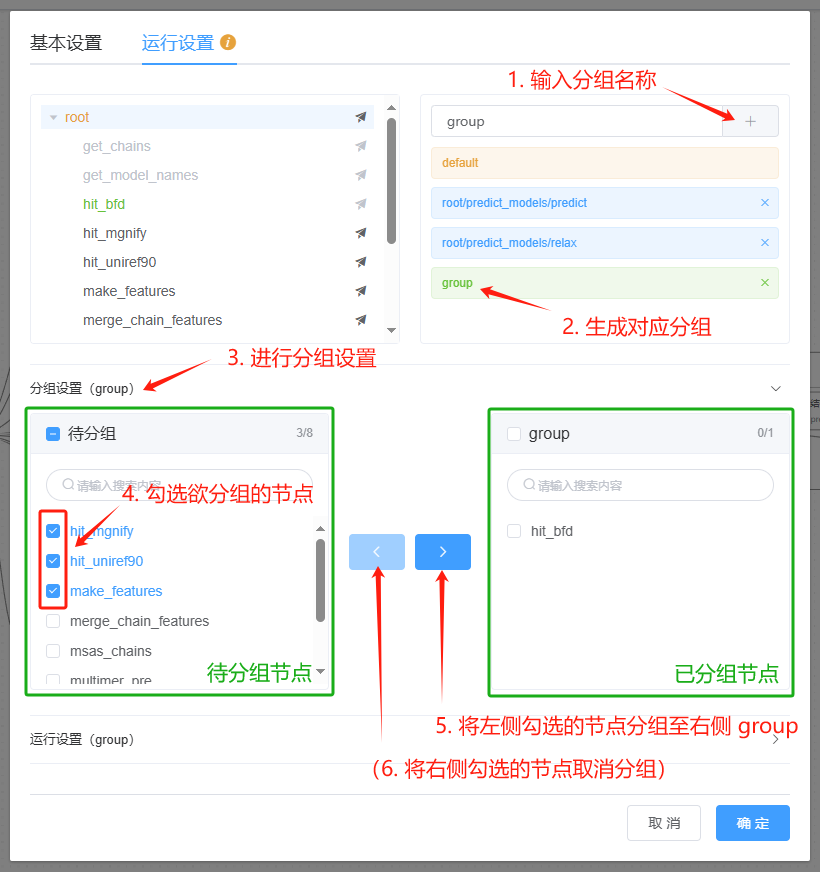
对分组进行 运行时配置
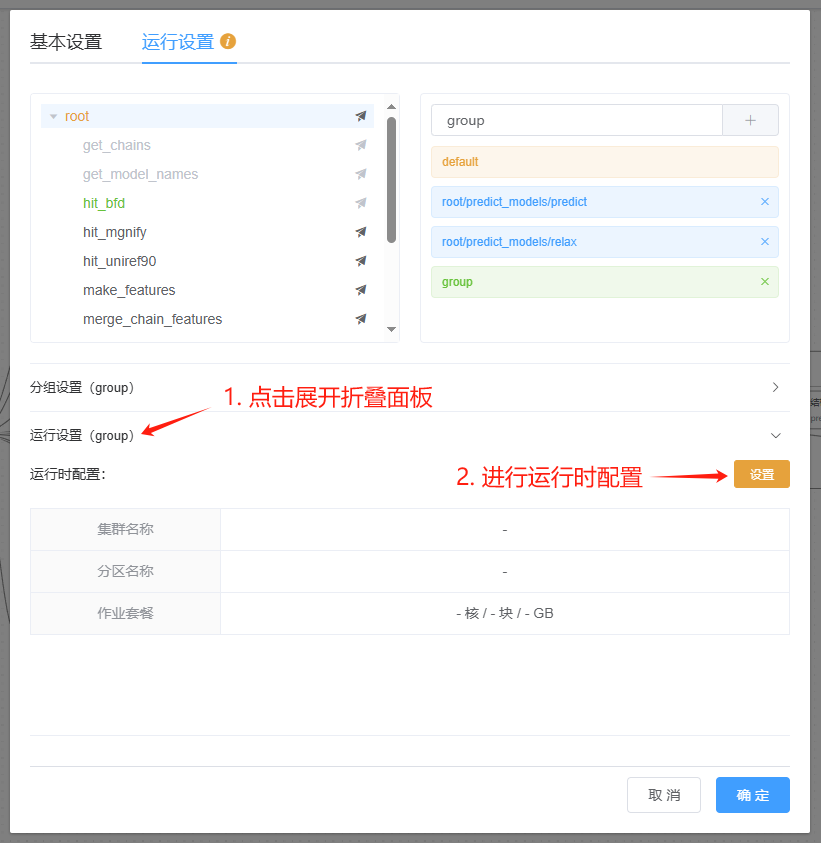
运行时配置¶
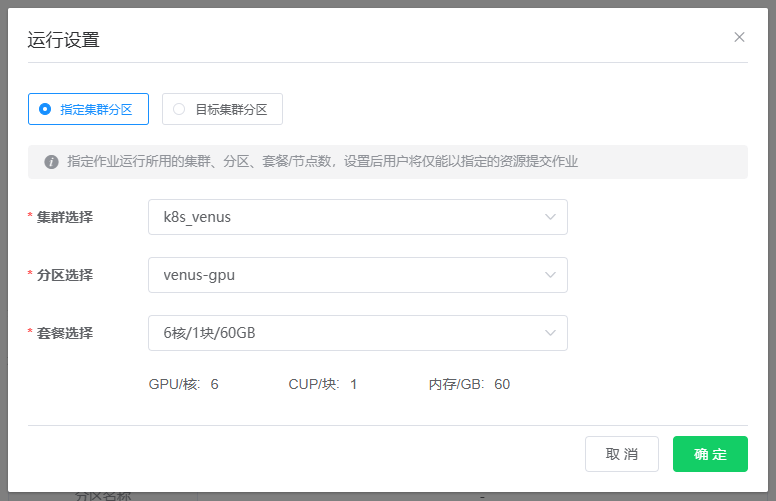
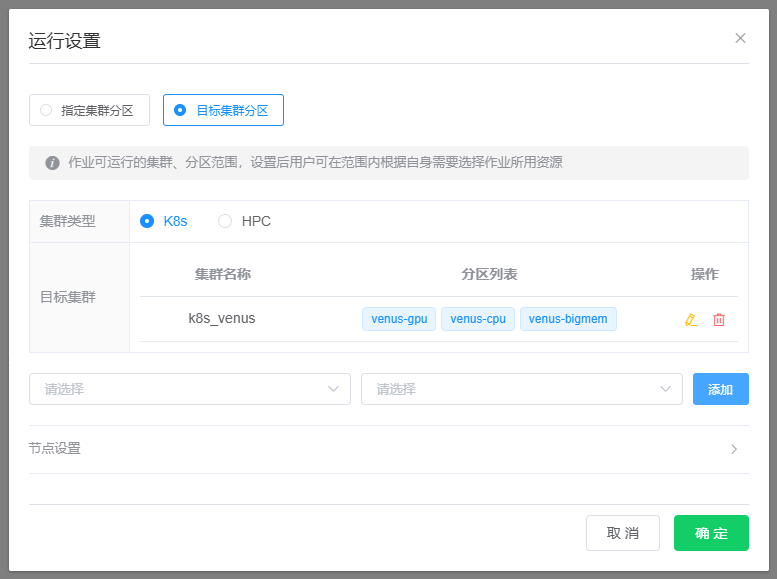
运行设置 页中,有两种指定节点运行环境的方法:
指定集群分区:指定工作流运行集群分区,用户提交作业时不可修改
目标集群分区:设置可选集群分区范围,在用户提交作业时可以在设定范围内选择
直接编辑 CWL 代码¶
目前星光工作流遵循 CWL 1.1 标准,兼容部分 1.2 标准特性。关于 CWL 请参考 Common Workflow Language

点击 编辑代码 按钮,可以通过编辑 CWL 文档的方式来创建工作流。
编辑完成后,需要点击 解析 按钮。星光会根据文档内容推断出图形结构,并保存编辑的数据。
在进行可视化编辑的过程中,可以随时通过编辑 CWL 功能来进行流程的修改。
附录¶
表达式¶
一些属性的定义可以使用表达式,通过 JS 代码执行得到结果。
表达式的语法有 $(...) 和 ${...} 两种,均遵循 ECMAScript 5(也被称 JS5) 标准,其中 $(...) 内部必须为一个 ECMAScript expression, ${...} 则为一个 ECMAScript function body。
在表达式中,可以使用 inputs 来索引当前节点 执行过程 中定义的 输入参数 列表中的变量,为 Object 类型,键为参数变量的 id ,值为用户提交作业时传入的参数值(类型与变量类型一致)。在一些场景下还可以使用 self 变量,其值依场景而不同,不同场景对表达式执行结果的预期也不同。
输入表达式¶
用于对输入参数进行额外的逻辑处理,生成输入参数的值
对应
普通应用/输入参数/行为属性/绑定到命令行参数/表达式或工作流应用/计算任务/执行过程/输入参数/输入绑定/表达式取值CommandLineTool.inputs.inputBinding.valueFromself 表示当前输入参数项的输入值
表达式的执行结果需与输入参数的类型相匹配,工作流执行器会自动根据输入参数的类型进行转换,转换失败时报错
小技巧
输入绑定中可以使用表达式来进一步处理输入内容。
访问 self 来获取原始的输入,访问 inputs 来获取其他输入。
参考示例:
调整输入的内容,从原整型输入修改为字符串:
--size=$(self)MB如果输入是文件类型,可以读取其内容:
$(self.contents || '')(注意:需要打开 “解析文件” 开关)读取其它
输入参数的值拼接成当前输入参数的值:$(inputs.workdir)/$(inputs.filename)
命令表达式¶
用于动态生成命令行参数,与
输入表达式类似,但不直接对应具体的输入参数项对应
普通应用/添加参数/参数表达式或工作流应用/计算任务/执行过程/执行命令CommandLineTool.arguments执行结果需要为字符串
小技巧
命令的每个部分都可以使用表达式来定义参数内容,表达式的计算结果应该是 字符串 类型的。
访问 inputs 来引用输入。
可参考下列示例:
直接将输入 A 作为参数:
--PROP_A=$(inputs.A)(该场景更推荐直接使用输入的前缀属性来实现)根据开关 B 的状态赋值:
$(inputs.B?"-O3":"-g -O0")将输入的数组用特殊的符号分隔以供程序识别:
$(inputs.arr.join("; "))
环境变量表达式¶
用于定义与输入参数关联的环境变量
对应
普通应用/配置信息/运行环境/环境变量设置/环境变量值或工作流应用/计算任务/执行过程/其他属性/其他设置/环境变量支持/变量值CommandLineTool.EnvVarRequirement.envDef执行结果需要为字符串
小技巧
可以使用表达式来定义环境变量,表达式的计算结果应该是 字符串 类型的。
访问 inputs 来引用输入。
可以参考下列示例:
直接将输入 A 赋值给环境变量:
$(inputs.A)根据开关 B 的状态赋值:
$(inputs.B?"product":"debug")为输入 C 添加一个前缀再赋值给环境变量:
PREFIX_$(inputs.C)根据输入的长度 I 和元素 E 产生数组:
${ var arr = []; for ( var i = 0; i < inputs.I; i++ ) arr.Push(inputs.E); return arr.toString(); }
输出参数匹配表达式¶
用于定义匹配模式以匹配输出文件
对应
普通应用/配置信息/结果参数/匹配文件或工作流应用/计算任务/执行过程/输出参数/输出绑定/通配符匹配CommandLineTool.inputs.inputBinding.glob执行结果需要为字符串
小技巧
可以使用表达式来动态生成匹配模式,表达式的计算结果应该是 字符串 类型的。
可以参考下列示例:
根据输入文件 infile 的文件名生成匹配模式:
$(inputs.infile.basename).txt匹配运行时输出目录中的所有 .txt 文件:
$(runtime.outdir + "/*.txt")
输出参数表达式¶
用于进一步处理匹配到的输出文件
对应
普通应用/配置信息/结果参数/表达式或工作流应用/计算任务/执行过程/输出参数/输出绑定/表达式取值CommandLineTool.inputs.inputBinding.outputEvalself 为
File[]类型,表示 输出参数匹配表达式 获取到的文件列表表达式结果必须与当前输出参数定义的类型一致
小技巧
输出绑定 中可以使用 表达式取值 属性,在匹配到输出文件后,使用 JavaScript 表达式对其进行进一步处理。
访问 self 变量来获取当前输出参数 匹配模式 所匹配到的文件。访问 inputs 变量来引用输入参数的值。对于文件类型的输出参数,可以访问其 contents 属性来获取其内容。
可以参考下列示例:
直接取第一个匹配到的文件:
$(self[0])直接读取第一个文件的第 2 行(数组从 0 开始,所以下标是 1 ):
$(self[0].contents.split('\n')[1] || '')返回所有匹配到的文件名:
$(self.map(function(e) {return e.path || ''}))
JS表达式节点中的表达式¶
通过JS表达式来定义一个
执行过程对应
工作流应用/JS表达式/执行过程/表达式ExpressionTool.Expression需要 使用一个
${...}结构,返回一个与输出参数定义一致的 JS 对象。
执行条件表达式¶
根据表达式结果控制此节点是否需要执行
对应
工作流应用/工作流节点/执行条件需要 返回布尔值类型结果
CWL 类型系统¶
CWL 基础类型:
null:空值boolean:布尔值,true / falseint:32 位有符号整数long:64 位有符号整数float:单精度(32 位)IEEE 754 浮点数double:双精度(64 位)IEEE 754 浮点数string:Unicode 字符串File:文件对象Directory:目录对象
File 类型属性:
class:固定值File,标识对象类型为文件location:文件的 URI 位置,在工作流中处理时,对于文件系统中的文件,会使用file://前缀进行标记path:文件的本地路径basename:文件的基本名称,即不包含路径的文件名dirname:文件所在目录的路径nameroot:文件名的主体部分,不包含扩展名nameext:文件的扩展名checksum:文件内容的校验和size:文件大小,单位为字节secondaryFiles:与主文件相关的次要文件列表format:文件的格式,通常是一个 URI 来指定文件格式contents:文件的内容,需要 “读取文件” 的功能打开
Directory 类型属性:
class:固定值Directory,标识对象类型为目录location:目录的 URI 位置path:目录的本地路径basename:目录的基本名称,即不包含路径的目录名listing:目录中文件和子目录的列表,每个都是File或Directory对象
除此之外,CWL 还有高级类型。高级类型由基础类型组合而成,或者使用特殊的类型符号来表述,主要有以下三类:
Record:自定义类型,较为复杂,不展开叙述,若有需要可参考 CommandInputRecordSchema 与 CommandOutputRecordSchema
Enum:枚举类型,可以理解为一个限定范围的字符串。有如下属性:type:固定为Enum,表示对象类型为枚举symbol:一个字符串数组,表示可接受的取值
Array:数组类型,可以表示任意类型的数组。有如下属性:type:固定为Array,表示对象类型为数组items:一种类型或多种类型关键字组成的数组,表示数组可容纳的元素类型
可用的类型符号缩写:
基础类型数组可以在基础类型的结尾使用
[]表示,例如string[]等效于{ "type":"array", "items": "string" }对于单一类型可缺省的场景,可以使用
?表示,例如string?等效于["string", "null"]备注
输入/输出参数的类型
type允许接收一个类型列表,用于表示该参数支持多种类型的输入/输出,列表项中有 null 时,表示该参数可以缺省。例如["string", "int", "null"]表示该参数支持传入 string 类型、int 类型与 null 类型(即可缺省)的数据。
循环功能实现¶
备注
该部分涉及到的循环功能的细节,通常情况下您不需要关心。但这些细节可能在您需要了解工作流的具体执行逻辑时有所帮助。
需求声明¶
与其他 CWL 的功能类似,循环功能也需要指定对应的需求才能启用。这有利于在将文档迁移到其他平台时及时发现不兼容的情况以便做出修改。
指定 LoopFeatureRequirement 来启用循环功能,我们为同时为支持该功能的文档定义了一个新的版本号 v1.2+loop (后者不强制使用):
class: Workflow
cwlVersion: v1.2+loop
requirements:
- LoopFeatureRequirement: {}
循环属性¶
定义循环功能使用的属性是 loop,这个属性是工作流节点(即 WorkflowStepParameter )的一部分:
steps:
step1:
in:
in1: in1
in2: in2
out: [out1]
run: add.cwl
loop:
history: false
until: $(iter > 10)
patch:
in1:
source: out1
valueFrom: $(inputs.in1 + outputs.out1 + iter)
上面的示例展示了 loop 属性的所有子属性:
history:是否记录循环中每次迭代的输入输出以便于后续处理,若为 false 或未指定,则只记录最后一次迭代的结果until:循环的退出条件,该属性中的表达式如果计算结果为 true 则结束循环patch:每次循环迭代执行后的补丁(修改)
循环补丁¶
循环补丁本质是一个 map。它的 key 是每次迭代前需要更新的参数(即 in 部分中的某个输入参数),它的 value 是一个结构体,表示修改的方法。该结构体有下列属性可选:
source:指定一个输出(out中的某个输出参数)作为新值来源valueFrom:指定一个表达式作为新值来源。若同时指定了source,可以使用 self 来访问source指定的输出
循环相关表达式¶
循环功能的定义中,有两个属性需要使用到表达式, 结束条件 until 和修改输入参数的表达式取值 valueFrom。为了使这些表达式能够处理循环功能中需要的条件,我们定义了下列的变量以供表达式使用:
inputs:本次迭代计算的输入outputs:本次迭代计算的输出iter:本次迭代计算的索引,从 0 开始self:本次迭代计算所修改的输入参数的数据源,仅valueForm可用
示例文档¶
备注
此处提供的实例文档可以直接用于创建一个工作流应用,您可以复制文档后,直接使用导入 CWL 功能创建一个工作流并借以修改。参考 直接编辑 CWL 代码。
scatterTest¶
备注
分发 Scatter 功能的使用参考
class: Workflow
cwlVersion: v1.0
inputs:
- default:
- class: File
path: /ExampleFileSystem/UserHome/log.install.sn02
- class: File
path: /ExampleFileSystem/UserHome/log.install.sn02
- class: File
path: /ExampleFileSystem/UserHome/log.install.sn02
- class: File
path: /ExampleFileSystem/UserHome/log.install.sn02
id: file1
type: File[]
outputs:
- id: count_output
outputSource:
- step1/output
type: int[]
requirements:
- class: ScatterFeatureRequirement
steps:
- id: step1
in:
- id: file1
source:
- file1
out:
- output
run:
baseCommand:
- wc
class: CommandLineTool
cwlVersion: v1.0
inputs:
- id: file1
inputBinding: {}
type: File
outputs:
- id: output
outputBinding:
glob:
- output.txt
loadContents: true
outputEval: $(parseInt(self[0].contents))
type: int
requirements:
- class: InlineJavascriptRequirement
stdout: output.txt
scatter:
- file1
testExp¶
备注
cwl 表达式使用示例
class: Workflow
doc:
inputs:
- id: mapfile
loadContents: true
type: File
outputs:
- id: mapkeys
outputSource:
- getID/mapkeys
type: string[]
- id: uniqKeys
outputSource:
- getID/uniqKeys
type: string[]
steps:
- id: getID
in:
- id: mapstr
source:
- mapfile
valueFrom: $(self.contents)
label: getID
out:
- mapstr
run:
class: ExpressionTool
doc: |-
此 ExpressionTool 期望的输入是一个 JSON 字符串,
此过程则按一定规则处理分析此字符串,
得到 mapkeys 和 uniqKeys 两个字符串列表
expression: |-
${
var mapstr = inputs.mapstr;
var mapdata = JSON.parse(mapstr);
var mapkeys = Object.keys(mapdata);
var seqs = {};
var uniqKeys = [];
for (var i in mapkeys) {
var k = mapkeys[i];
var seq = mapdata[k]["sequence"];
if (!seqs[seq]) {
seqs[seq] = k;
uniqKeys.push(k);
}
}
return { "mapkeys": mapkeys, "uniqKeys": uniqKeys };
}
inputs:
- id: mapstr
type: string
outputs:
- id: mapkeys
type: string[]
- id: uniqKeys
type: string[]
testArrayArray¶
class: Workflow
cwlVersion: v1.2
doc: |-
此例使用了CWL中的一些高级特性,如:
* array type
* InitialWorkDirRequirement
一些特性现阶段比较难通过图形化操作进行编辑;但可以通过 编辑CWL 功能进行补充完善
hints: []
inputs:
- id: message
type: string
intent: []
outputs:
- id: outmsg
outputSource:
- dumpFile/outfiles
type:
items: File[]
type: array
requirements: []
steps:
- id: create2file
in:
- id: message
source:
- message
label: create2file
out:
- outmsg
run:
baseCommand:
- sh
- example.sh
class: CommandLineTool
inputs:
- id: message
type: string
outputs:
- id: outmsg
outputBinding:
glob:
- msg*.txt
type: File[]
requirements:
- class: DockerRequirement
dockerPull: >-
hub.starlight.nscc-gz.cn/nsccgz_duliang_1_public/ubuntu-1606286629:18.04
- class: InitialWorkDirRequirement
listing:
- entry: |-
date > msg1.txt
echo "$(inputs.message) $(runtime.cores)" >> msg1.txt
date > msg2.txt
echo "$(inputs.message)" >> msg2.txt
sync
entryname: example.sh
- id: dumpFile
in:
- id: msgFile
source:
- create2file/outmsg
label: dumpFile
out:
- outfiles
run:
arguments:
- "-c"
- >-
cat $(inputs.msgFile.path) > out1.txt && cat $(inputs.msgFile.path) >
out2.txt && sync
baseCommand:
- bash
class: CommandLineTool
inputs:
- id: msgFile
type: File
outputs:
- id: outfiles
outputBinding:
glob:
- "*.txt"
type: File[]
requirements:
- class: DockerRequirement
dockerPull: >-
hub.starlight.nscc-gz.cn/nsccgz_duliang_1_public/ubuntu-1606286629:18.04
scatter:
- msgFile
- id: countCond
in:
- id: msgFile
source:
- create2file/outmsg
label: countCond
out:
- outfile
run:
baseCommand:
- echo
- do nothing
class: CommandLineTool
outputs:
- id: outfile
type: stdout
requirements:
- class: DockerRequirement
dockerPull: >-
hub.starlight.nscc-gz.cn/nsccgz_duliang_1_public/ubuntu-1606286629:18.04
when: $(inputs.msgFile.length > 2)