作业管理¶
作业列表¶
平台左侧导航栏中点击 我的作业,进入作业管理界面。
运行中作业¶
作业管理界面上方有 运行作业 和 历史作业 两个标签,点击 运行作业 标签,进入运行中作业列表,如下图:
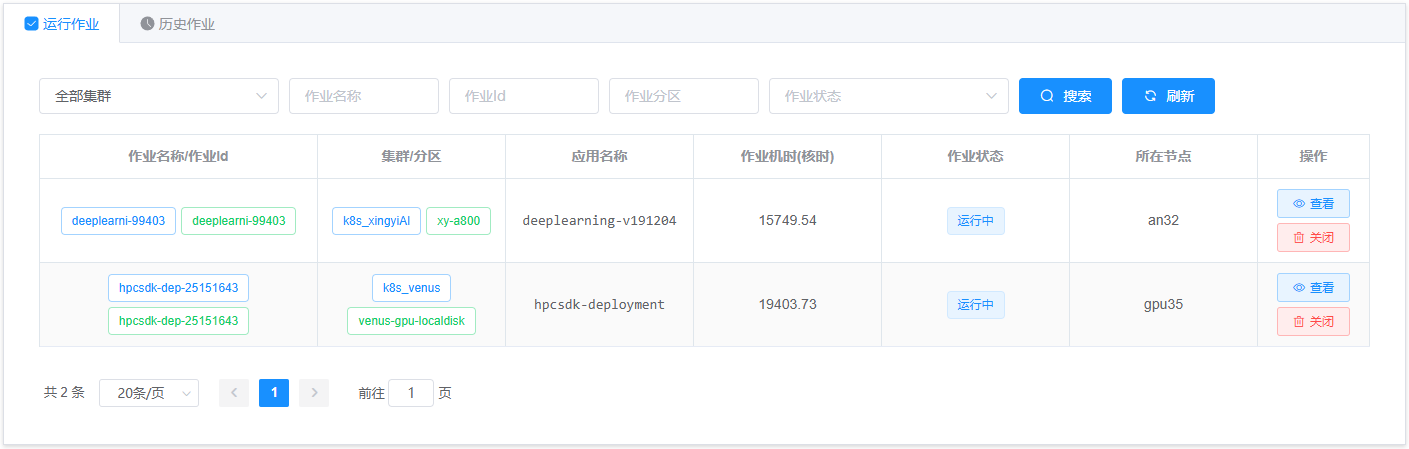
列表中显示了当前账号正在运行的作业,显示的作业信息包括作业名称、作业 id、作业分区、应用名称、作业机时(核时)、作业状态、所在节点。
作业状态包括:
排队中:等待调度的作业
挂起:暂停运行资源未释放的作业
运行中:正在运行中的作业
已结束:成功结束的作业
已结束(失败):失败退出的作业
创建失败:创建失败的作业
已取消:用户或管理员取消的作业
创建中:已分配资源,在进行运行环境的初始化
退出码异常:作业非正常退出,请确认后主动关闭
未知:未知的作业状态
故障:运行中但不可用
在界面上方可以根据作业 所在集群、 作业名称 、 作业id 、 作业分区 以及 作业状态 对作业进行筛选。
在列表的 操作 列中:
点击 “查看” 按钮,可以进入该行对应作业的详情页面,详情参考 作业详情;
点击 “关闭” 按钮,可以结束作业。
备注
当且仅当作业状态为 运行中 或 排队中 才可在 “运行中作业列表” 关闭;否则需要点击 “查看” 按钮进入 作业详情 界面进行关闭动作(此时可以通过作业详情中的 “查看日志” 和 “状态说明” 检查作业状态不正常的原因)。
历史作业¶
点击用户作业管理界面 历史作业 标签,进入历史作业列表,如下图:
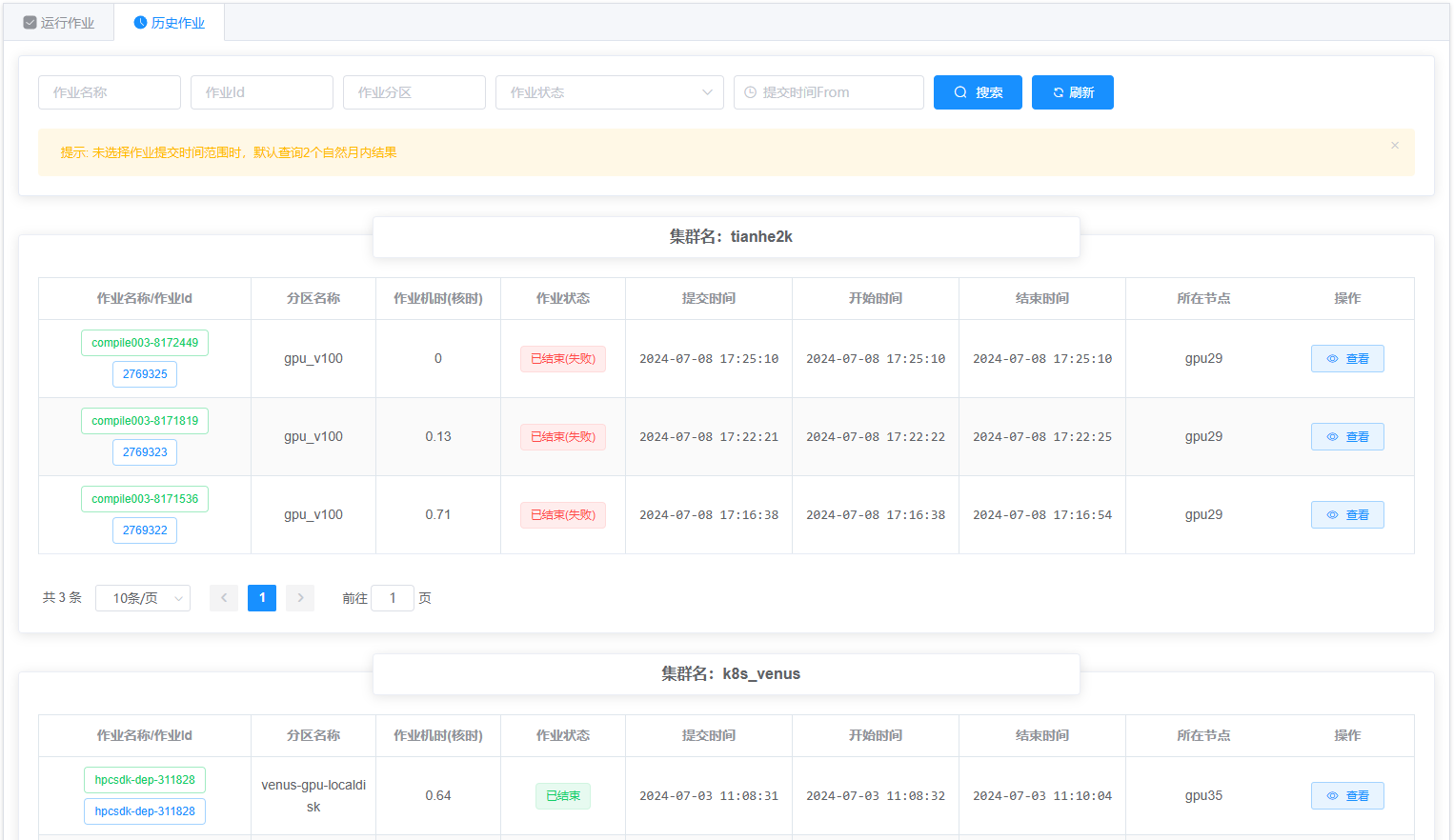
列表中以 “集群” 为单元对用户的历史作业进行展示,显示的作业信息包括作业名称、作业 id、作业分区、作业机时(核时)、作业状态、提交时间、开始时间、结束时间、所在节点。
可以根据 作业名称 、 作业id 、 作业分区 、 作业状态 、 提交时间 对作业进行筛选。
点击 操作 列中的 “查看” 按钮,可以进入该行对应作业的详情页面,详情参考 作业详情。
作业详情¶
点击 运行作业 列表或 历史作业 列表中的作业项的 “查看” 按钮,进入作业详情界面,如下图是一个 容器应用 类作业的 “作业详情” 界面:
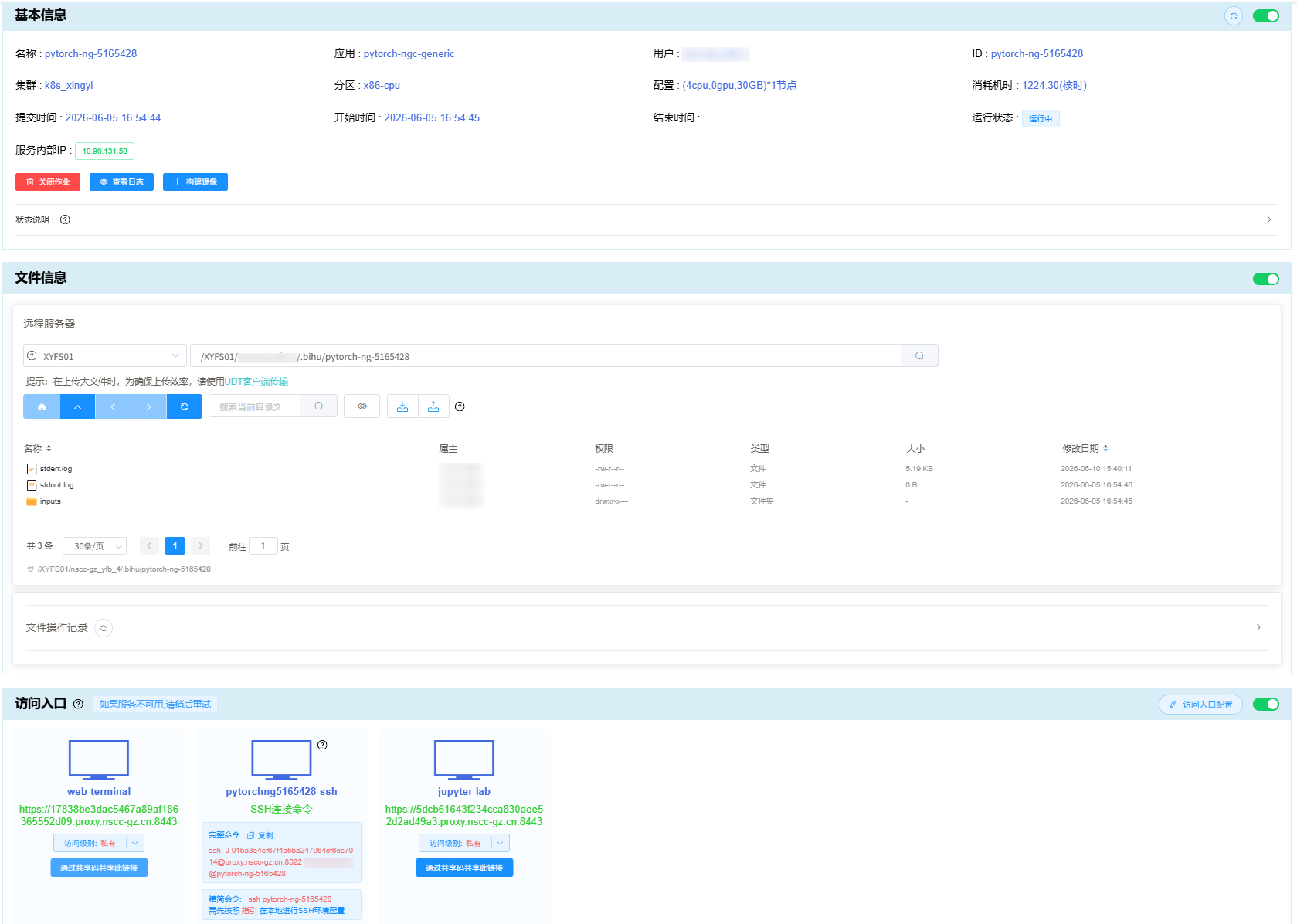
作业详情界面包括作业 基本信息 、 文件信息 、 访问入口 三部分。
基本信息¶
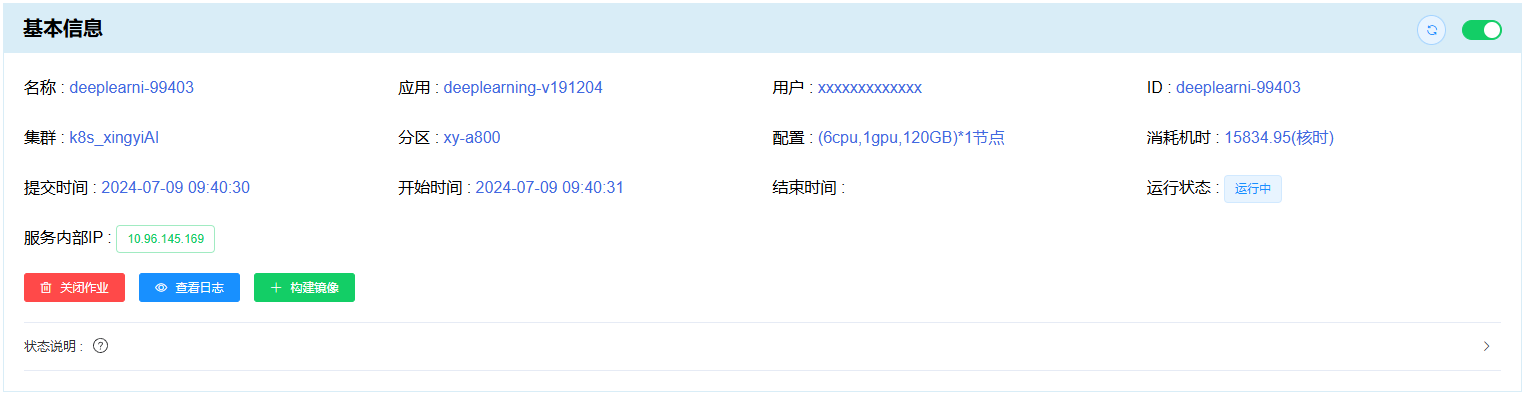
基本信息 除展示作业的基本信息(如作业所在的 集群、 分区 信息, 状态说明 等 )外,还有 “关闭作业” 、“查看日志”(仅限容器类应用的作业)、“构建镜像”(仅限容器类应用的作业)、“性能监控” 等功能。
关闭作业¶
点击 “关闭作业” 按钮,弹出确定关闭作业窗口,点击 “确定” 按钮,关闭作业。
查看日志¶
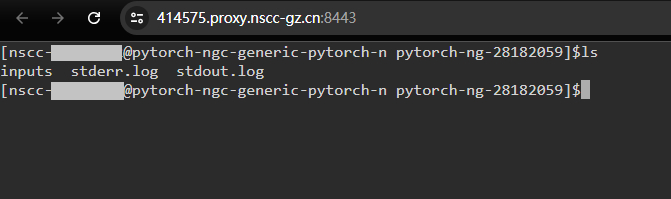
点击 “查看日志” 按钮,弹出作业运行日志窗口,显示容器的运行日志,即容器内 1 号进程的输出,如下图:
构建镜像¶
将容器类作业所在虚拟容器运行环境的当前状态固化为一个新的容器镜像,对应 docker commit 功能。
构建成功的容器镜像会保存到 镜像仓库 中,可以在 镜像管理 查看,并支持新作业以此镜像为基础创建虚拟运行环境,详见 容器应用 镜像选择。
点击 “构建镜像” 按钮,弹出 构建镜像 窗口,如下图:
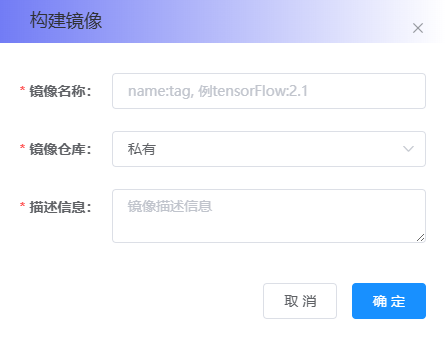
在 构建镜像 窗口中,填写 镜像名称 和 描述信息,点击 “确定” 按钮,则可跳转至 镜像管理 界面,并开始构建镜像。
状态说明¶
对于容器类作业, 状态说明 包含三部分:
Status: 容器当前的状态Conditions: 容器运行需要的各项状态条件,会按状态条件逐条进行说明Events: 与这个作业相关的事件信息
用于记录该作业关闭前的系统信息,说明作业处于某种状态的原因。
对于已经结束的作业,此处没有内容,或显示的内容为作业运行时 状态说明 最后时刻的内容,历史状态信息可能会被覆盖。
备注
用户可以根据 状态说明 信息来分析当前作业状态是否正常。
示例 1
Status: Running Conditions: Initialized Ready ContainersReady PodScheduled Events: 2021-06-04 14:20:19 +0800 CST Normal Scheduled Successfully assigned 1870/bashkuber2-414207-qvskb to cpn255 2021-06-04 14:20:20 +0800 CST Normal Pulling Pulling image "hub.starlight.nscc-gz.cn/nscc_public/deeplearning-1574907288:centos" 2021-06-04 14:20:20 +0800 CST Normal Pulled Successfully pulled image "hub.starlight.nscc-gz.cn/nscc_public/deeplearning-1574907288:centos" 2021-06-04 14:20:20 +0800 CST Normal Created Created container bashkuber2-414207 2021-06-04 14:20:20 +0800 CST Normal Started Started container bashkuber2-414207这是一个正常运行中的作业
状态说明:Status为 “运行中” (Running),有些状态会在后面附加进一步的说明信息ConditionsInitialized为 “初始化完成”PodScheduled为 “资源调度完成”Ready为 “全部就绪”ContainersReady为 “容器就绪”
Events中可以看到成功完成了资源分配、镜像拉取、容器创建、容器启动等过程
在完成资源调度后(
PodScheduled),后台会对资源的使用开始计费,在资源释放后则停止计费。示例 2
Status: Failed Conditions: Initialized Ready ContainersNotReady containers with unready status: [bashkuber2-4145313] ContainersReady ContainersNotReady containers with unready status: [bashkuber2-4145313] Container bashkuber2-4145313 Error PodScheduled Events: 2021-06-04 14:53:32 +0800 CST Normal Scheduled Successfully assigned 1870/bashkuber2-4145313-rc448 to cpn224 2021-06-04 14:53:34 +0800 CST Normal Pulling Pulling image "hub.starlight.nscc-gz.cn/nsccgz_xxxx_public/deeplearning-1574907288:centos" 2021-06-04 14:53:34 +0800 CST Normal Pulled Successfully pulled image "hub.starlight.nscc-gz.cn/nsccgz_xxxx_public/deeplearning-1574907288:centos" 2021-06-04 14:53:34 +0800 CST Normal Created Created container bashkuber2-4145313 2021-06-04 14:53:34 +0800 CST Normal Started Started container bashkuber2-4145313这是一个运行一段时间后出错退出的作业
状态说明:Status为失败(Failed)ConditionsInitialized“初始化完成”Ready条件未达成,因此后面会有未达成的原因ContainersNotReady,即 “容器未就绪”,再后面是对应的消息containers with unready status: [bashkuber2-4145313]ContainersReady条件未达成,将逐一显示容器的状态(同一资源请求可以包含多个容器创建),即示例中的Container bashkuber2-4145313 Error
示例 3
Status: Pending Conditions: Initialized Ready ContainersNotReady containers with unready status: [elasticsea-41506] ContainersReady ContainersNotReady containers with unready status: [elasticsea-41506] Container elasticsea-41506 ContainerCreating PodScheduled Events: 2021-06-04 15:00:17 +0800 CST Normal Scheduled Successfully assigned 1870/elasticsea-41506-585f76994c-6gzth to cpn31 2021-06-04 15:00:20 +0800 CST Normal Pulling Pulling image "hub.starlight.nscc-gz.cn/nsccgz_xxxx_public/elasticsearch-1579573612:7.5.1"这是一个处于拉取镜像状态的作业示例
状态说明:Status为创建中(Pending),因为尚有未就绪的条件ConditionsContainersReady条件未达成, 从Container elasticsea-41506 ContainerCreating信息可以看出,未达成的原因是尚还处于容器创建的过程中,结合Events信息看,目前尚在进行镜像拉取
如果镜像较大,计算结点第一次拉取镜像时可能会较为耗时,用户在使用自定义镜像时需合理控制镜像大小。
性能监控¶
当作业所在节点启用了性能监控功能,作业 基本信息 模块将显示 “性能监控” 按钮。
备注
目前部署有性能监控的有 tianhexy-ai 集群、tianhexy-a 集群、k8s_xingyiAI 集群、k8s_xingyiAI_2 集群、k8s_ss01 集群。
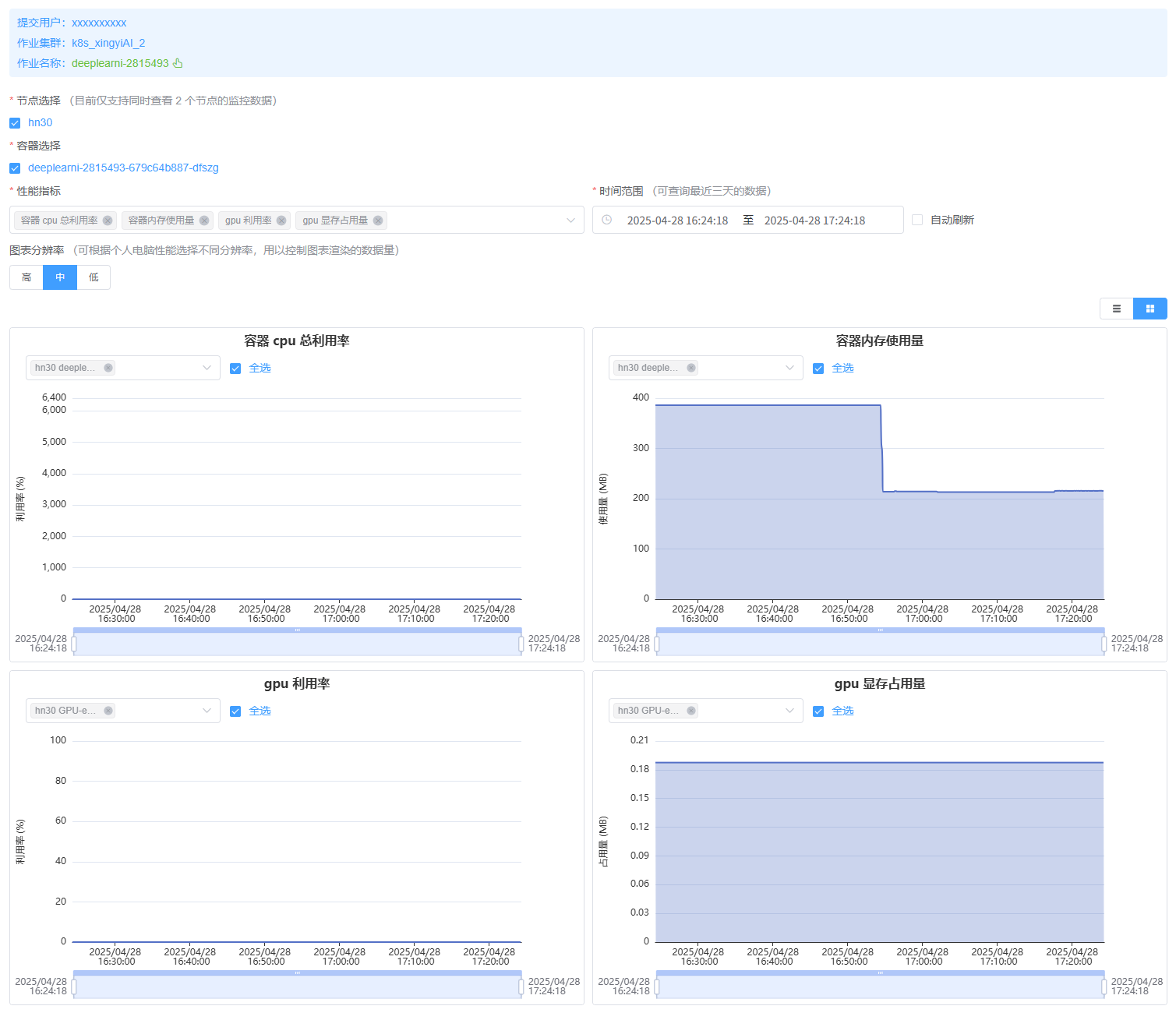
点击 “性能监控” 按钮则可跳转至性能监控界面,对作业进行性能监控,如下图:
小技巧
当作业为多节点作业时,性能监控界面可最多同时显示 2 个节点的性能指标。可在 “节点选择” 中切换要监控的节点。
当作业为容器作业并存在多个容器时,可在 “容器选择” 中选择要监控的容器。
默认只会展示 4 项性能指标,最多允许同时展示 6 项指标。可在 “性能指标” 下拉框中切换自己感兴趣的性能指标进行展示。
默认只会展示最近 1 小时的性能数据,可在 “时间范围” 下拉框中切换展示不同时间范围的性能数据。最长可展示最近 3 天的性能数据。
对于 IB 网络读写带宽的性能数据,当选择的时间跨度较小时将自动切换到毫秒精度展示。
可勾选 “自动刷新” 按钮开启自动刷新功能,开启后性能监控图表将自动刷新展示最新的性能数据。
可根据自己的电脑配置情况,在 “图表分辨率” 中自由切换
高中低三种分辨率,以控制图表渲染的数据量大小。当作业分配了多种设备时,可在性能图表的下拉框中选择要监控的设备。
在性能图表上可以拉动下方的时间轴,单独对某张图表的性能数据进行时间范围的调整。
性能诊断¶
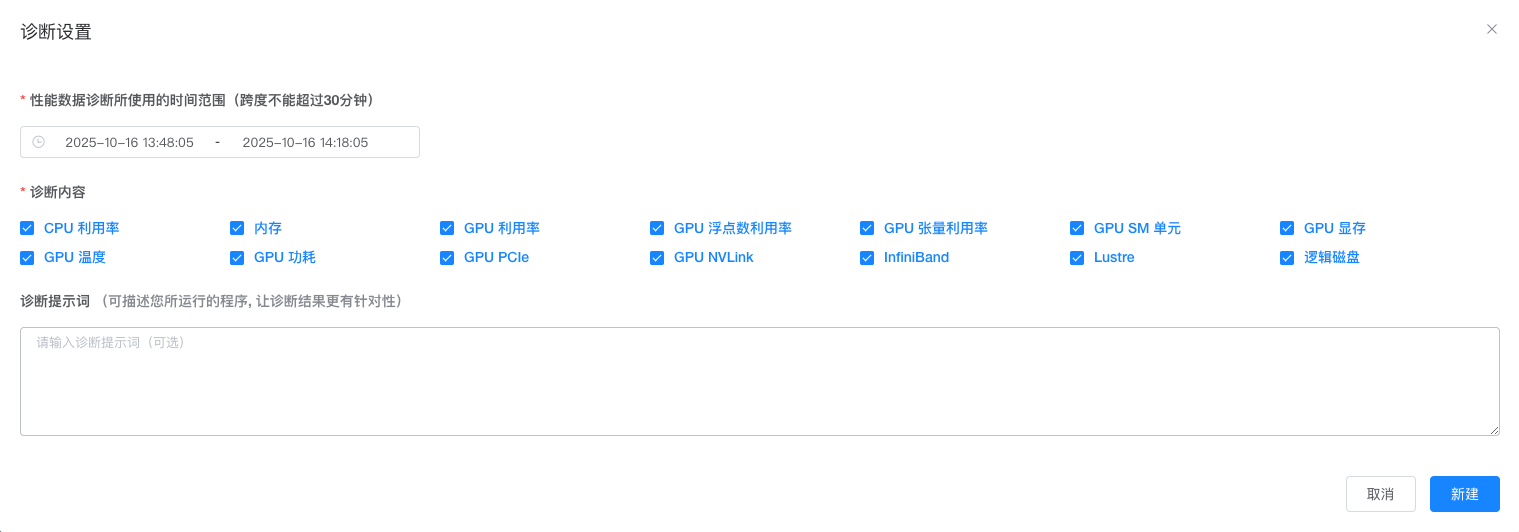
在 性能监控 界面,可点击 “新建诊断” 按钮来新建一个性能诊断任务,后台将自动分析该作业的性能数据和异常事件,分析完成后给出诊断结果(如性能优化建议、异常处理建议等)。如下图所示:
小技巧
新建诊断任务时默认会对作业最近 30 分钟的性能监控数据进行分析。可在 “时间范围” 选择器中根据实际需求调整分析的时间范围。选择分析的时间跨度不能超过 30 分钟。
在 “诊断内容” 中可以根据需求调整需要诊断的性能指标项,默认会对所有性能指标进行诊断。所选择的指标项不一定越多越好,根据实际需求进行选择即可。
在 “诊断提示词” 中可以自定义诊断任务的分析提示词,最好能对所选时间段内运行的程序进行详细说明,让诊断结果更有针对性。
所有设置调整完毕之后即可点击 “新建” 按钮,新建一个性能诊断任务,该任务将在后台自动分析作业的性能数据和异常事件,分析完成后将给出诊断结果。
诊断任务会在后台异步执行,可在 性能监控 界面点击 “诊断结果” 按钮进行查看。如下图所示:
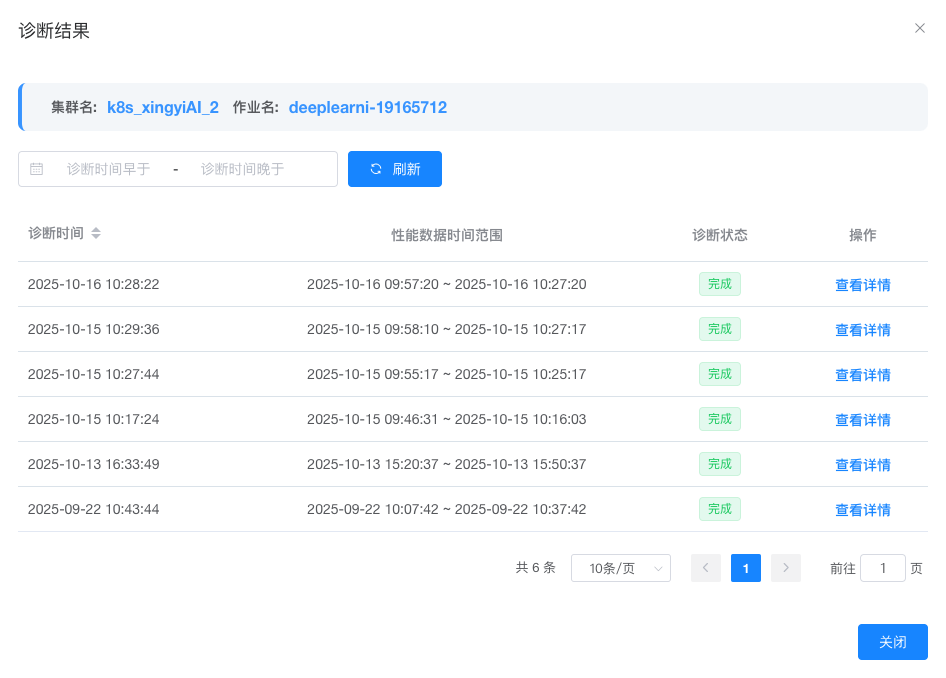
备注
可按照诊断任务的诊断时间对历史诊断结果进行排序。
可选择状态为 “完成” 的诊断任务,点击 “查看详情” 按钮来查看该任务的详细诊断结果。如下图所示:
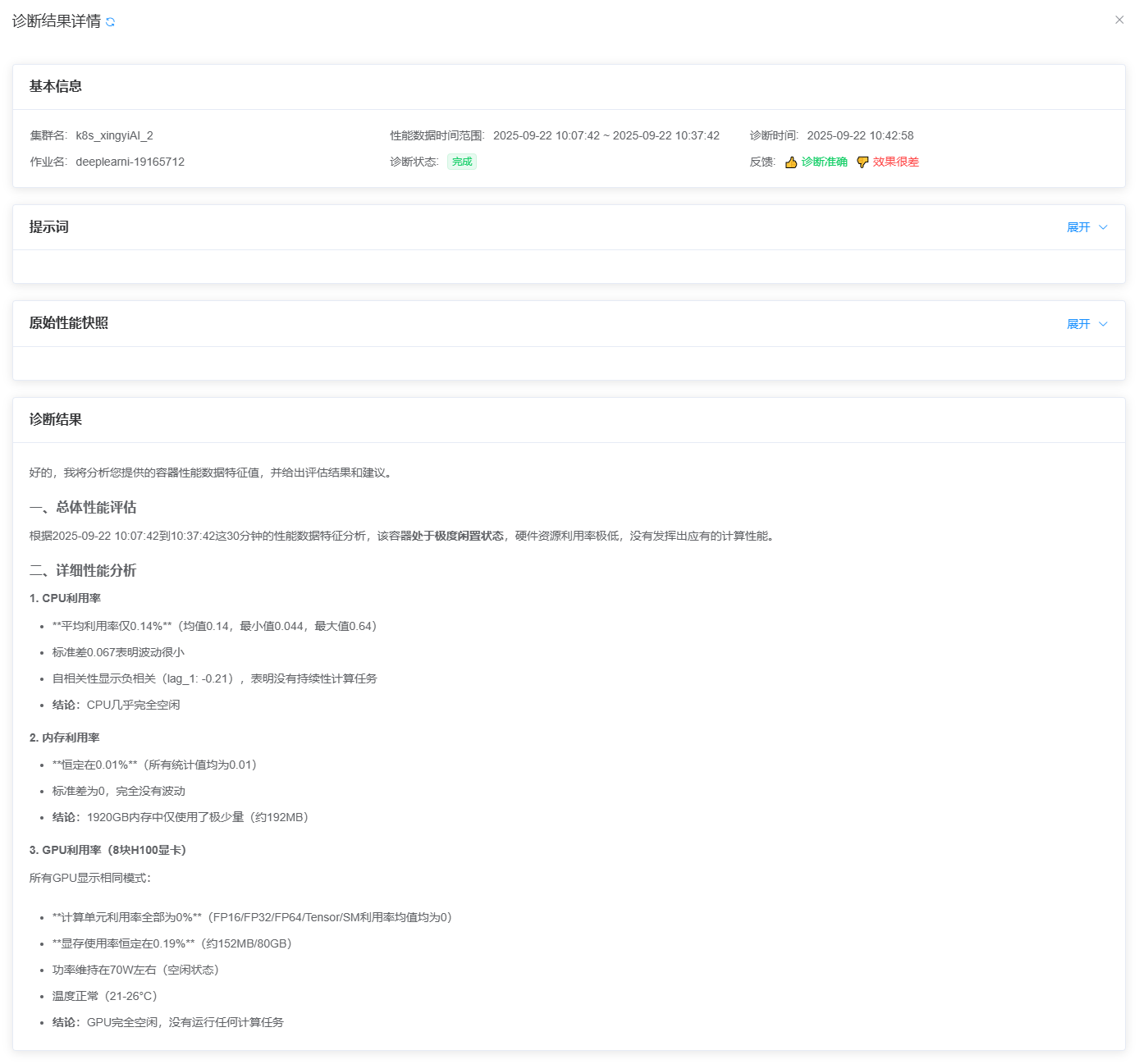
小技巧
诊断结果中包含了对作业性能数据和异常事件的详细分析说明,用户可根据说明进行相应的优化或处理。
可展开
原始性能快照,按照诊断结果对比原始性能数据图表,判断诊断结果是否准确。您可在 “反馈” 处点击 “诊断准确” 或者 “效果很差”,对我们的诊断结果进行反馈,帮助我们改进诊断算法和模型。
文件信息¶
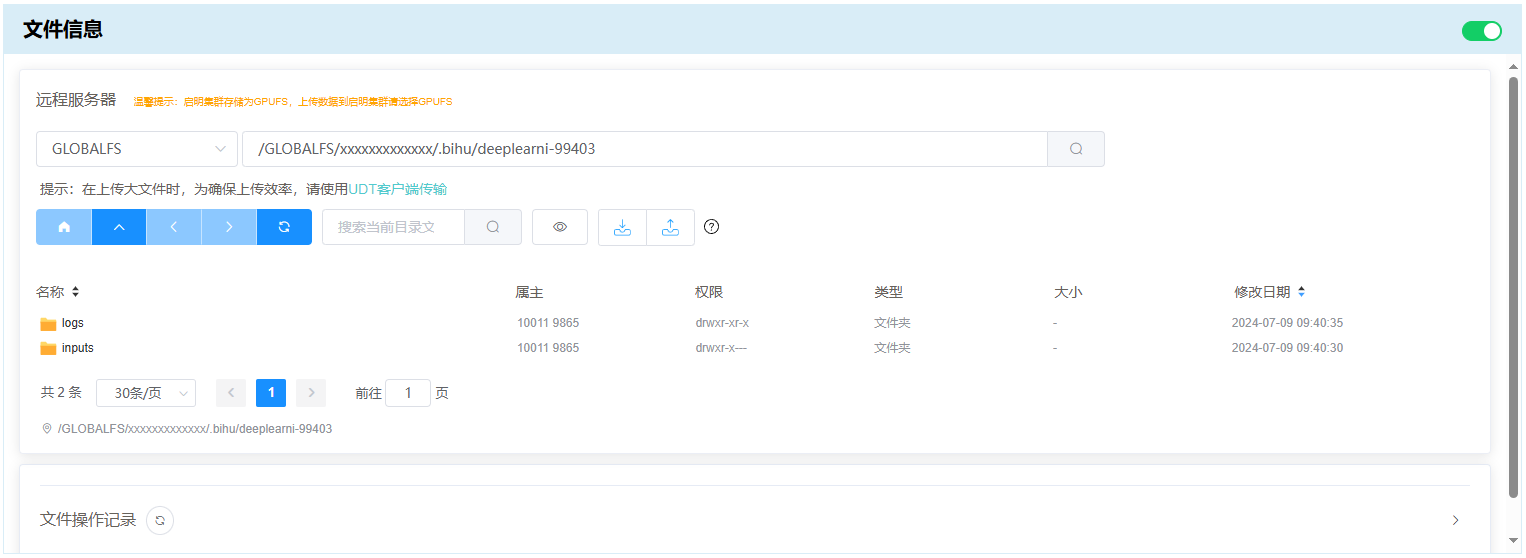
用户提交作业后,平台会新建一个文件夹作为作业的工作目录。进入作业详情界面后, 文件信息 部分将显示作业工作目录下的文件,如上图中作业的工作目录为 “/GLOBALFS/xxxxxxxxxxxxx/.bihu/deeplearni-99403”。
若所运行应用的执行逻辑没有进行切换工作目录动作,则作业运行产生的文件默认保存在该目录下,用户可以在此处管理作业运行产生的文件(若有进行切换工作目录动作,则作业运行产生的文件需要用户自己维护)。
访问入口¶
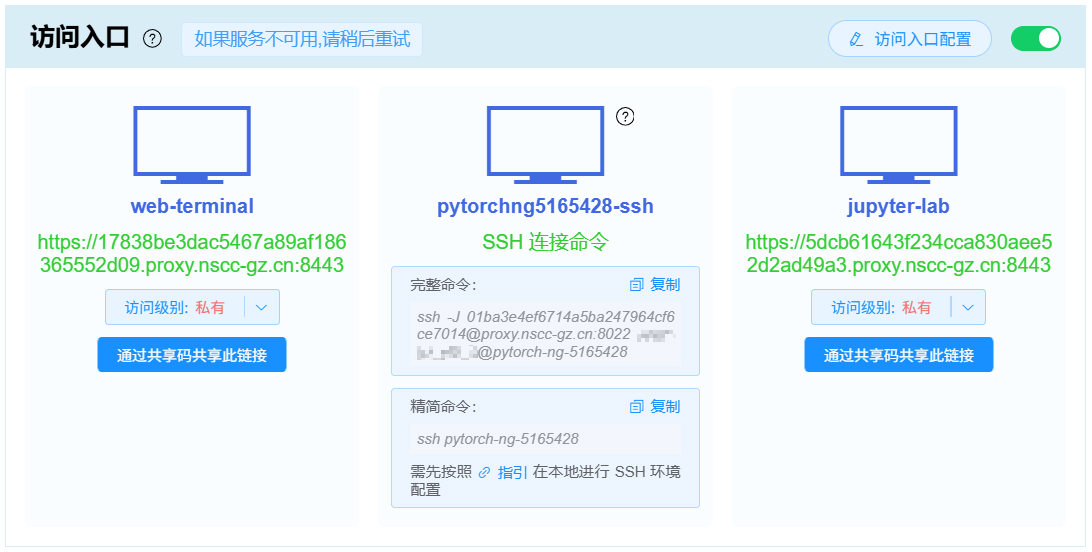
容器云应用所预留的交互操作入口,供用户连入观察作业运行过程中的资源使用情况。
访问入口设置¶
在 作业详情 的 访问入口 区域,点击 “访问入口配置” 按钮,弹出访问入口设置界面,如下图:

添加访问入口¶
点击 “添加” 按钮,弹出添加访问入口界面,如下图:
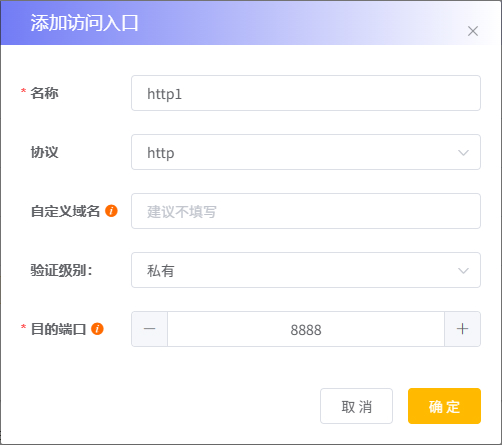
各项信息说明如下:
名称自定义的访问入口名称,用于区分不同的访问入口,不可与已有访问入口名称重复。
协议代理入口使用的协议,可选 http、https、ssh 和 tcp。
验证级别生成的代理链接的验证级别,可选的级别有:
私有、登陆用户、不验证。各级别说明如下:私有该级别的访问入口只有作业运行者本人可以使用,但可以通过共享码的方式共享给其他人。
通过共享码共享访问入口
在
访问入口区域,对于成功启用的访问入口,点击 “通过共享码共享此链接” 按钮,即可输入共享码并共享该访问入口,如下图: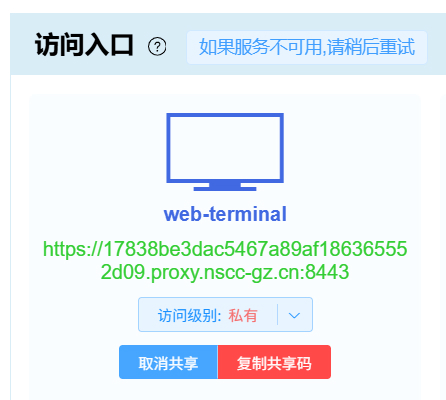
点击 “复制共享码” 按钮,将共享码分享给需要的星光用户,对方登录星光平台后便可在浏览器中通过共享码访问分享的资源,如下图:
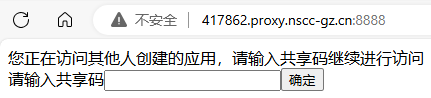
点击 “取消共享” 按钮,取消共享,则其他用户不能再访问。
登陆用户该级别的访问入口所有已登录的星光用户都可以访问
不验证该级别的访问入口不需要验证,任何人都可以访问。
目的端口需要访问的容器内部服务所监听的端口,不可与已有访问入口的目的端口重复。
完成相关信息填写后点击 “确定” 即可创建新的访问入口。
自定义域名¶
若用户需要使用自己的域名访问代理入口,可进行域名自定义:
小心
用户必须将域名映射到公网 IP [121.46.19.23],具体操作方式请参照域名服务商的官方文档,以 阿里云 为例。
公网 IP 可能会重新分配,用户可通过
ping 1.proxy.nscc-gz.cn
进行查询,如下图所示:

将访问入口的
协议设置为 “https” 或 “http” 并输入已注册备案过的域名,如下图所示: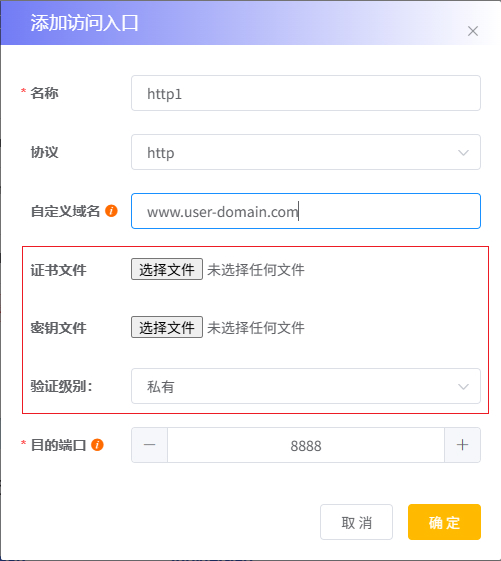
表单项说明
自定义域名该项仅在选择 https 和 http 协议时出现,使用已注册备案过的域名,直接通过该域名访问代理入口。
证书文件该项仅在选择 https 和 http 协议且设置有自定有域名时出现,用于上传 https 证书文件。
密钥文件该项仅在选择 https 和 http 协议且设置有自定有域名时出现,用于上传 https 密钥文件。
上传域名对应的证书文件与密钥文件。
完成其余信息填写后点击 “确定” 创建新的访问入口,创建成功后用户即可直接通过所设置的域名访问代理入口。
删除访问入口¶
在 修改访问入口 窗口点击欲删除的访问入口项的 “移除” 按钮,再点击 “确认” 即可删除相关访问入口。
访问入口使用¶
网页终端¶
若具备名为 ttyd、 webssh、 web-terminal 等的访问入口,则可以直接通过浏览器以终端的方式连接到作业运行的容器里。如下图:
点击 web-terminal 访问入口,会弹出一个作业容器内的网页终端界面,如下图:
ssh 连接¶
若容器作业内启动了 ssh 服务,并正确建立了相应的 ssh 协议的访问入口,则可通过 ssh 工具登录作业。
备注
若需在容器作业内启动 ssh 服务及建立访问入口,请参考 容器访问工具 章节。
ssh 直接连接¶
如下图,在 访问入口 中,可以看到作业的 SSH 访问入口:
可以使用命令 ssh -J <入口UUID>@proxy.nscc-gz.cn:8022 <用户名>@<作业ID> 并按照提示输入密码后连接到作业运行的容器中。
备注
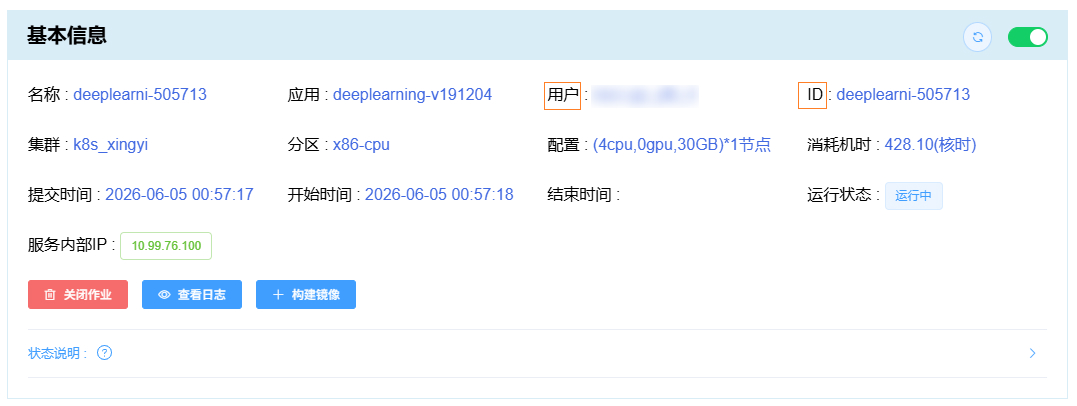
用户名 为星光用户名,可见 “作业详情” \(\rightarrow\) “基本信息” 中的 用户 项,
作业ID 为作业的唯一标识,可见 “作业详情” \(\rightarrow\) “基本信息” 中的 ID 项
如下图所示:
连接需要输入的 password 为用户登录星光所用的密码。
如果需要免密码登录,则需要进行 ssh 密钥配置 中的相关配置。
ssh 精简命令连接¶
配置好本地 ssh 环境后,还可使用精简命令 ssh <作业ID> 连接。对于本地ssh环境配置,平台提供了手动配置和自动化配置两种方式。
本地ssh环境自动化配置¶
为了简化操作,您可在 ssh 访问入口的配置指引弹窗中,根据操作系统下载对应的自动化配置脚本并在本地执行。
Windows 系统
下载
<作业ID>.bat文件到本地,双击执行即可自动完成 ssh 环境配置。MacOS / Linux 系统
下载
<作业ID>.sh文件到本地,在终端下执行:bash <作业ID>.sh
配置完成后,即可使用精简命令 ssh <作业ID> 连接容器,不需要输入密码,因为已经配置了 ssh 免密码登录。
本地ssh环境手动配置¶
您可以在自己电脑上的 ssh 配置文件中添加以下内容:
Windows 系统:配置文件在
C:\Users\<您的电脑用户名>\.ssh\configLinux / MacOS 系统:配置文件在
~/.ssh/config
Host <作业ID>
StrictHostKeyChecking no
LogLevel ERROR
User <星光用户名>
ProxyCommand ssh -p 8022 -W <作业ID>:22 <入口UUID>@proxy.nscc-gz.cn
其中:
<作业ID>:容器的唯一标识<星光用户名>:您在星光平台的用户名<入口UUID>:访问入口的唯一标识
备注
<您的电脑用户名> 是您自己电脑的登录用户名,与 <星光用户名> 不是同一个。
本地ssh环境手动配置完成后,即可使用精简命令 ssh <作业ID> 连接容器,但是会提示需要输入密码,输入该用户的星光密码即可。
如要免密码登录,需要进行 ssh 密钥配置。
小心
自动化配置脚本会在本地自动创建所需的 ssh 目录、生成和修改 ssh 配置文件、自动生成密钥对并上传到容器中进行 ssh 免密码登录配置。如不想该脚本改动您的本地文件,请按照 本地ssh环境手动配置 进行操作。
容器作业关闭后容器的 ssh 登录配置将会无效,需要您自行清理配置。 清理方法如下:
删除容器对应的 SSH 配置文件
自动化配置脚本会在
~/.ssh/config.d/目录(Windows 下为C:\Users\<您的电脑用户名>\.ssh\config.d\)下为每个容器生成一个独立的配置文件,文件名为<作业ID>。容器作业关闭后可直接删除:Linux / MacOS:
rm ~/.ssh/config.d/<作业ID>Windows:
del C:\Users\<您的电脑用户名>\.ssh\config.d\<作业ID>或打开
C:\Users\<您的电脑用户名>\.ssh\config.d\目录,右击<作业ID>文件,选择 “删除”。
(可选)清理密钥对
自动化配置脚本在
~/.ssh/目录(Windows 下为C:\Users\<您的电脑用户名>\.ssh\)下生成的密钥对(<星光用户名>.id和<星光用户名>.id.pub)是所有容器共享的。如果您还有其他正在运行的容器作业, 请勿删除该密钥对。确认所有容器均已关闭后,可执行:Linux / MacOS:
rm ~/.ssh/<星光用户名>.id ~/.ssh/<星光用户名>.id.pubWindows:
del C:\Users\<您的电脑用户名>\.ssh\<星光用户名>.id C:\Users\<您的电脑用户名>\.ssh\<星光用户名>.id.pub或打开
C:\Users\<您的电脑用户名>\.ssh\目录,右击<星光用户名>.id和<星光用户名>.id.pub文件,选择 “删除”。
ssh 密钥配置¶
为避免每次都需要重新输入密码,您可以使用密钥来登录。由于星光容器作业能在不同的集群中提交作业,您可能没有在这些集群都配置 SSH 密钥,因此平台提供了为容器(所在集群)生成密钥并配置免密码登录的方法,您可以通过 网页终端 或者 ssh 直接连接 进入容器终端后按照以下步骤进行配置:
生成密钥
在容器的终端内,输入下列命令:
ssh-keygen -t rsa # 或者使用更新的 ed25519 算法,此时密钥文件为 id_ed25519 和 id_ed25519.pub # ssh-keygen -t ed25519回车后根据提示进行交互配置。通常不需要更改任何配置,只需要按回车键使用默认选项。执行完成后,
~/.ssh文件夹会被自动创建,其中包括了新生成的密钥对id_rsa和id_rsa.pub。添加公钥至授权列表
在密钥对生成完成后,我们需要授权这个密钥对。执行下列命令:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 600 ~/.ssh/authorized_keys下载并设置密钥访问权限
密钥生成后,使用
scp命令将私钥下载到本地。在您自己电脑的终端中执行:Windows 下(下载到桌面):
scp -J <入口UUID>@proxy.nscc-gz.cn:8022 <用户名>@<作业ID>:~/.ssh/id_rsa C:\Users\<您的电脑用户名>\Desktop\Linux / MacOS 下(下载到桌面):
scp -J <入口UUID>@proxy.nscc-gz.cn:8022 <用户名>@<作业ID>:~/.ssh/id_rsa ~/Desktop/
下载的密钥文件的权限可能过于开放,会被本地的 SSH 客户端或其他远程连接软件拒绝,此时需要修改其权限。
Linux 和 MacOS 下执行命令:
chmod 600 <密钥文件>Windows 下操作:
右击密钥文件,选择 “属性”
在 “属性” 页面的 “安全” 选项卡中,选择 “高级”
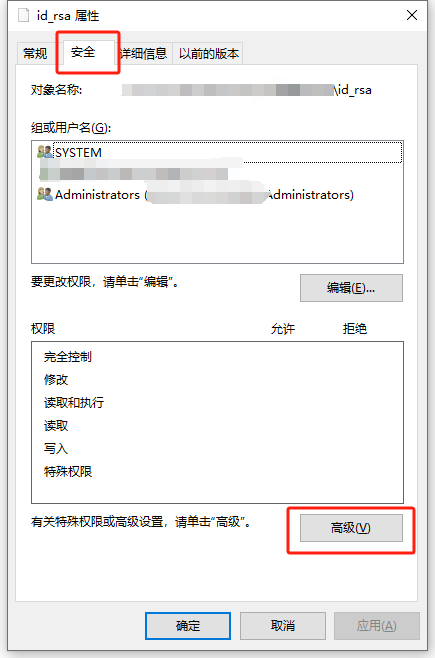
在 “高级” 窗口中,先启用 “禁用继承”,然后使用 “添加” 按钮为您自己添加一个权限
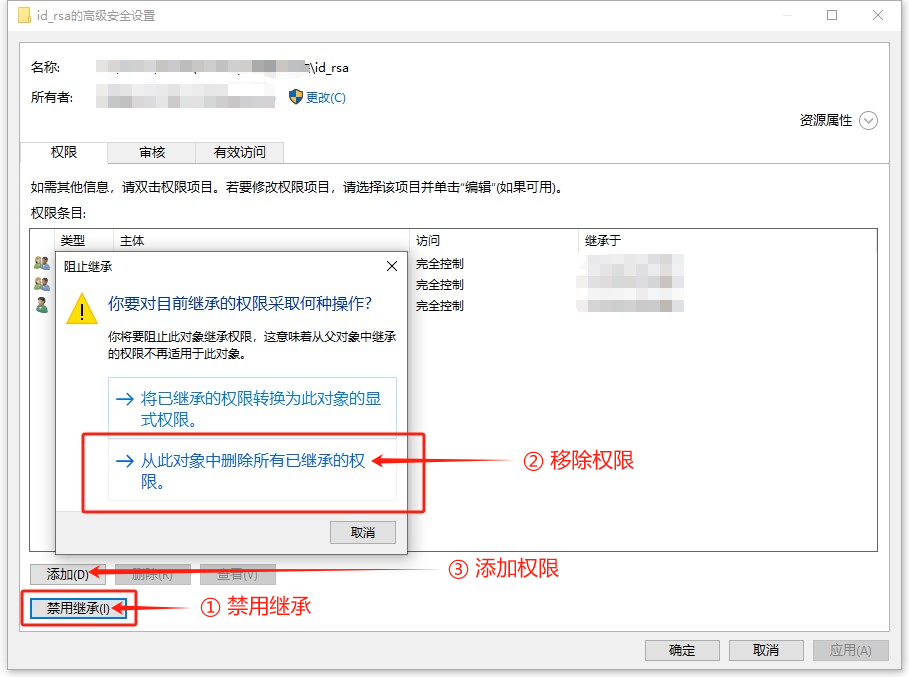
在弹出的窗口中,使用 “选择主体”,填写您自己的用户名,点击 “检查名称” 保证输入正确,然后点击确定
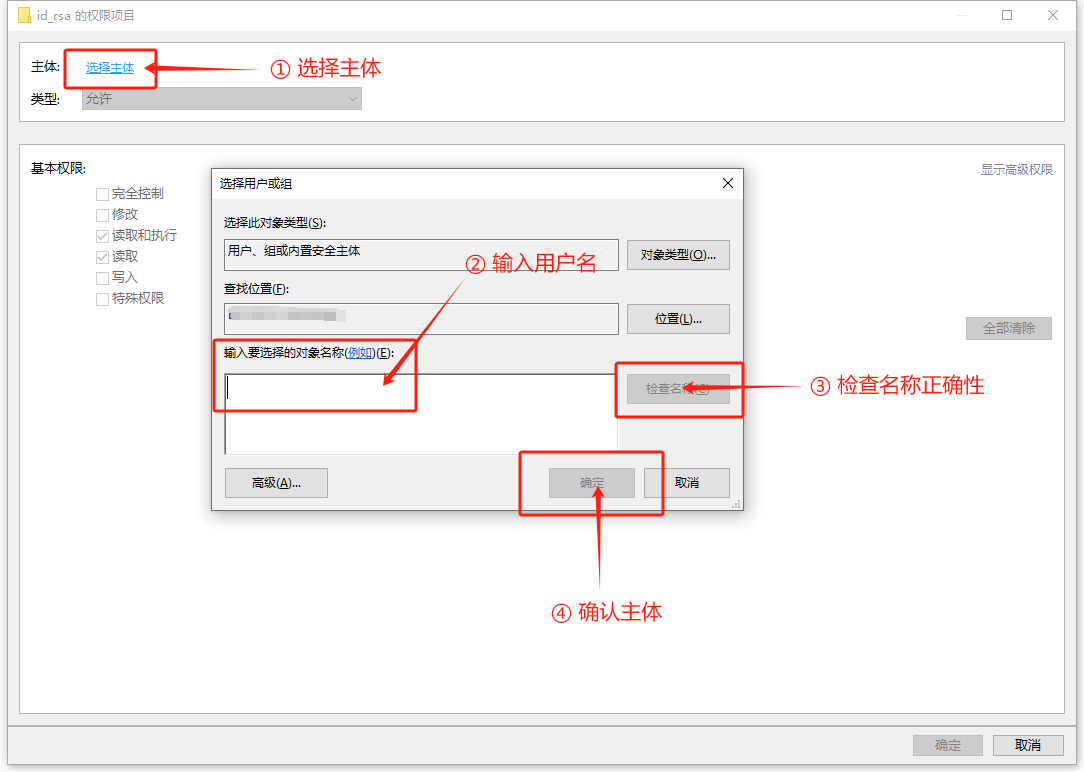
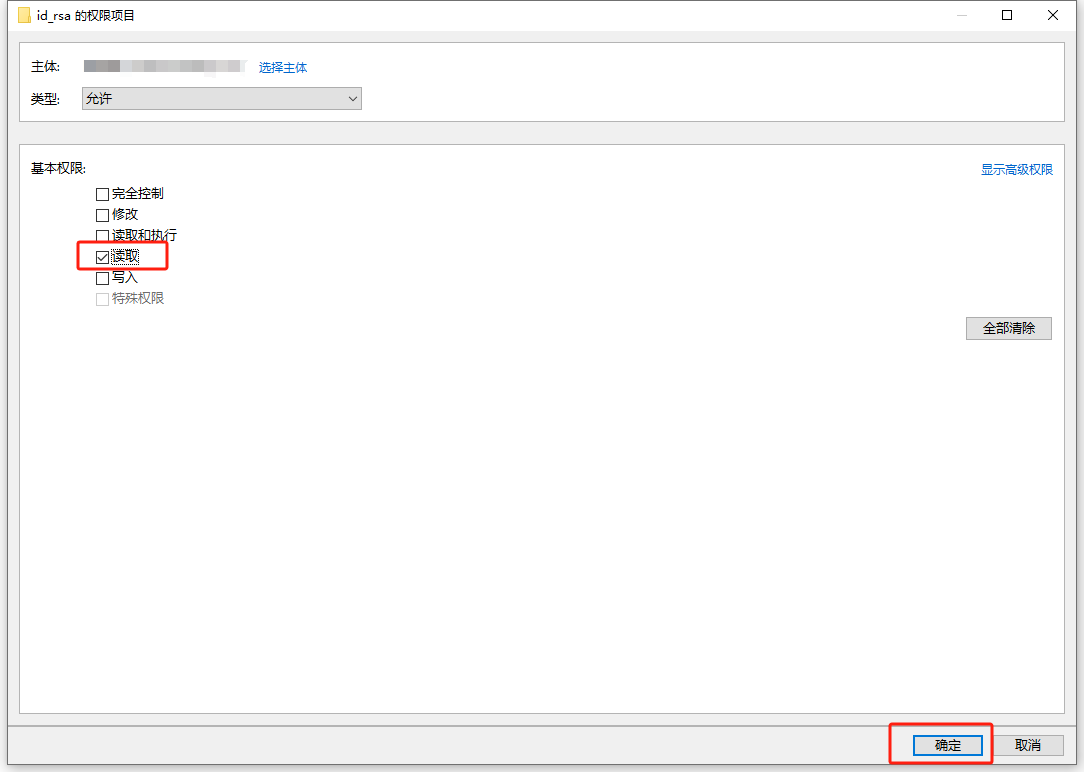
然后保证权限项仅勾选了 “读取” 项,点击 “确定” 来应用权限。
使用密钥访问容器
在 ssh 直接连接 的命令后通过 -i 选项即可指定密钥并进行连接:
ssh -J <入口UUID>@proxy.nscc-gz.cn:8022 <用户名>@<作业ID> -i <密钥文件>若已完成 ssh 精简命令连接 的相关配置,则在 ssh 配置文件中添加
IdentityFile <密钥文件路径>来指定连接该容器时使用的密钥文件,即可直接使用精简命令ssh <作业ID>来连接容器并免密码登录。ssh 配置示例如下:Host <作业ID> StrictHostKeyChecking no LogLevel ERROR User <星光用户名> ProxyCommand ssh -p 8022 -W <作业ID>:22 <入口UUID>@proxy.nscc-gz.cn IdentityFile <密钥文件路径>
vscode¶
vscode 使用前所需准备工作
在使用 vscode 进行 ssh 连接前,请确保本地 vscode 软件为 最新版本,并检查本地是否配置有网络代理,若有请关闭,避免影响连接。
若在完成上述准备工作后,仍无法成功通过 vscode 与容器作业建立远程连接,则需要为容器配置网络代理以保证容器内互联网的可访问性:
vscode 与容器作业建立远程连接时,会在容器中先进行初始化。而初始化过程以及后续的扩展下载等操作都需要联网,因此需要将集群上网代理配置进 ~/.bashrc 文件中, vscode 会使用该代理联网。
通过 ssh 直接连接 进入容器作业,在 ~/.bashrc 文件中 加载环境变量脚本:
echo -e "\nsource /app/bin/proxy.sh" >> ~/.bashrc
对 ~/.bashrc 文件的修改,除了会影响当前作业之外,所有投递于当前作业所投递集群的作业也均会受到影响,所以在不需要时,请将 ~/.bashrc 文件中的代理配置取消。
完成 ssh 精简命令连接 (手动配置 或 自动化配置 均可)后,即可在 vscode 中连接容器。
打开 vscode,按 F1 或 Ctrl+Shift+P 打开命令面板,输入/选择 "Remote-SSH: Connect to Host..."(或 "Remote-SSH: Connect Current Window to Host..."),在弹出的主机列表中可找到本地 SSH 配置中已配置好的容器,点击它即可连接,如下图:

备注
如果需要输入 密码,输入该用户的星光密码即可。
vscode 连接完成后效果如下:
PuTTY¶
PuTTY 自动配置¶
在 作业详情 的 SSH 访问入口的配置指引弹窗中,点击 PuTTY 下载链接,下载 <作业ID>.reg 文件到本地,双击该文件将相关配置导入注册表中,随后打开 PuTTY 即可在主机列表中看到已配置好的容器主机,双击它即打开链接窗口,按照提示输入 密码(password) 后回车即可登录到作业运行的容器中。
PuTTY 手动配置¶
首先在 作业详情 的 SSH 访问入口查询远程登录的作业ID、代理域名、代理入口UUID,如下图所示:

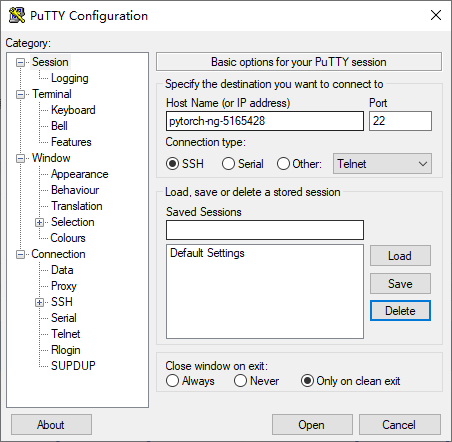
打开 PuTTY,在左侧 Category 选择 Session 窗口,在窗口中按如下方式填写:
"Host Name (or IP address)" 处填写
<作业ID>"Port" 处填写
22"Connection type" 处选择
SSH
如下图所示:
随后在左侧 Category 中选择 "Connection" \(\rightarrow\) "Proxy",在窗口中按如下方式填写:
"Proxy type" 处选择
SSH to proxy and use port forwarding选项"Proxy hostname" 处填写代理域名
proxy.nscc-gz.cn"Port" 处填写代理端口号8022
"Username" 处填写
<入口UUID>
如下图所示:
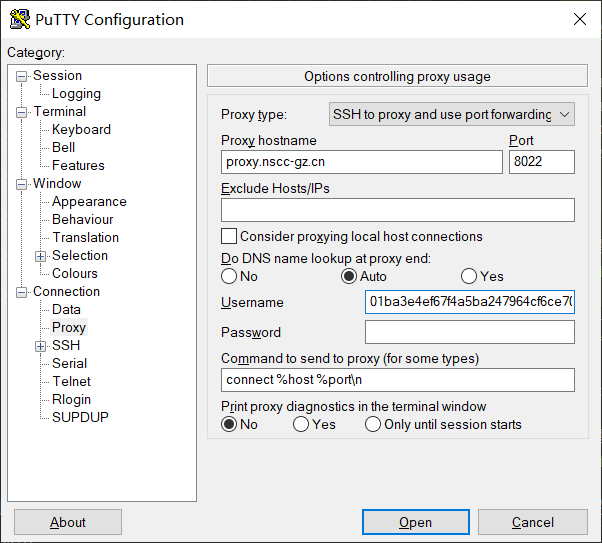
点击 “Open" 按钮后,按照提示输入 用户名(login as) 和 密码(password),输入完成后回车即可登录到作业运行的容器中。
PuTTY 免密登录¶
PuTTY 不支持直接使用 OpenSSH 格式的私钥文件,需要使用 PuTTYgen 工具将私钥转换为 PuTTY 专用的 .ppk 格式。
按照 ssh 密钥配置 中的步骤生成密钥并将
id_rsa私钥文件下载到本地。打开 PuTTYgen,点击 "Load" 按钮,在窗口右下角选择 "All Files (*)",选择您从容器中下载的私钥文件,加载成功后 PuTTYgen 会提示 "Successfully imported foreign key"。
点击 "Save private key" 按钮,将密钥保存为
.ppk格式文件(如id_rsa.ppk)。打开 PuTTY,在左侧 Category 中选择 "Connection" \(\rightarrow\) "SSH" \(\rightarrow\) "Auth" \(\rightarrow\) "Credentials",在 "Private key file for authentication" 处点击 "Browse" 选择刚才生成的
.ppk文件。配置完成后,后续使用 PuTTY 连接容器时即可免密码登录。
备注
密钥的生成和下载请参考 ssh 密钥配置。
也可以通过 PuTTYgen 直接生成密钥对:点击 "Generate" 按钮,按照提示移动鼠标生成随机数,然后将生成的公钥添加到容器的 ~/.ssh/authorized_keys 文件中,私钥保存为 .ppk 格式。
moba-xterm¶
moba-xterm 手动配置¶
首先在 作业详情 的 SSH 访问入口查询远程登录的作业ID、代理域名、代理入口UUID,如下图所示:
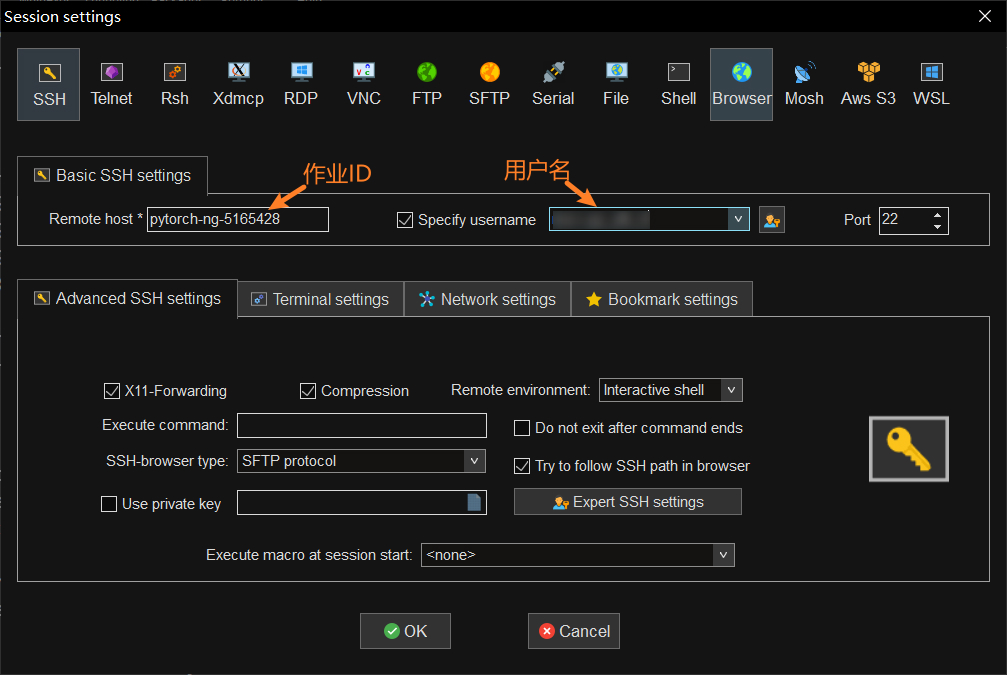
打开 MobaXterm,点击 "Session" \(\rightarrow\) "SSH",打开 Session settings 窗口,在窗口中按如下方式填写:
"Remote host" 处填写
<作业ID>"Specify username" 处打钩并填写您的星光用户名
"Port" 处填写
22
如下图所示:
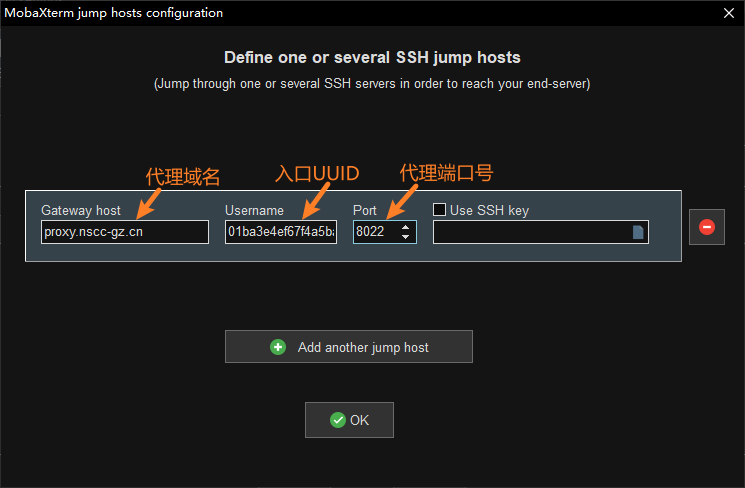
随后点击 "Network settings" \(\rightarrow\) "SSH gateway (jump host)" 打开 MobaXterm jump hosts configuration 窗口,在窗口中按如下方式填写:
"Gateway host" 处填写代理域名
proxy.nscc-gz.cn"Username" 处填写
<入口UUID>"Port" 处填写代理端口号8022
如下图所示:
点击 “OK" 按钮返回上一级界面,再点击 “OK” 确定后,会要求输入要登录的 密码 ,如下图所示:
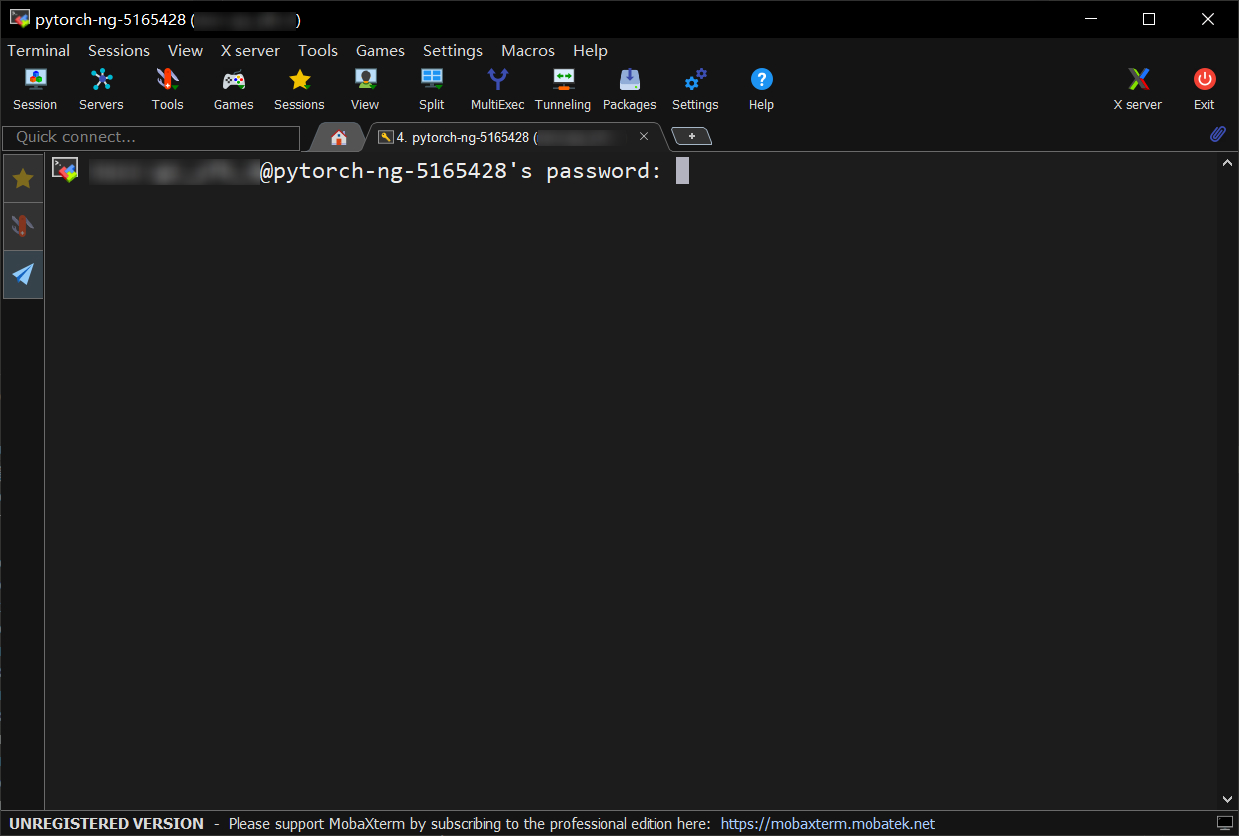
输入该用户的星光密码并回车即可登录到作业运行的容器中。
备注
用户名 为星光用户名,可见 “作业详情” \(\rightarrow\) “基本信息” 中的 用户 项:
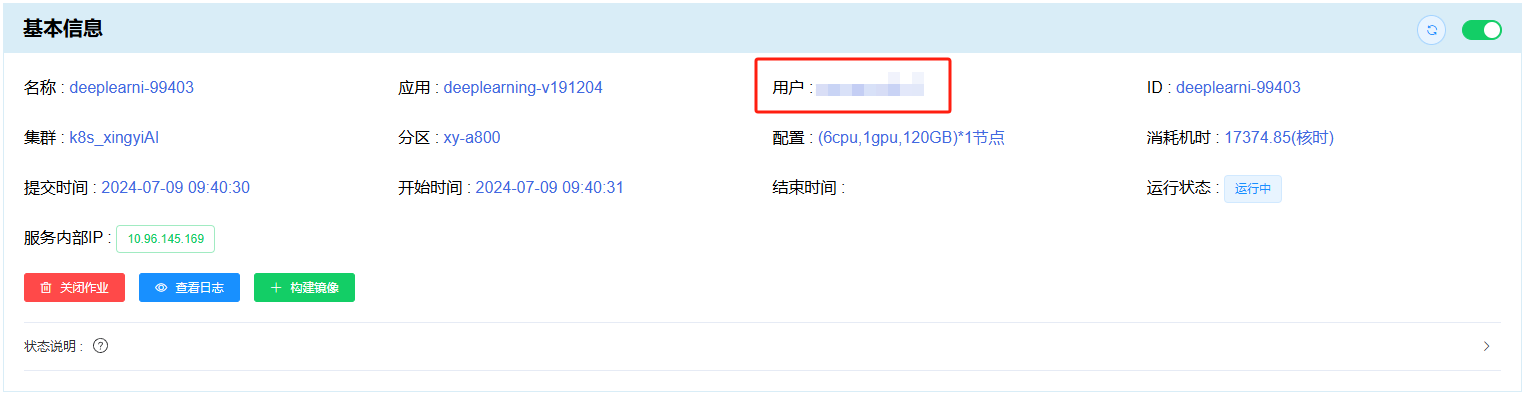
密码 为星光平台的登录密码。
如需免密登录,可按照 ssh 密钥配置 中的步骤生成密钥并将 id_rsa 私钥文件下载到本地,然后在 "Session settings" 窗口的 "Advanced SSH settings" \(\rightarrow\) "Use private key" 中指定该私钥文件路径。
moba-xterm 自动配置¶
在 作业详情 的 SSH 访问入口的配置指引弹窗中,点击 MobaXterm 下载链接,下载 <作业ID>.mxtsessions 文件到本地。打开 MobaXterm,在左侧 Sessions 会话列表中右键选择 "New folder" 新建目录(如 starlight),在该目录上右键选择 "Import sessions into this folder",导入下载的文件,再双击作业 ID 即可连接。
xshell¶
首先在 作业详情 的 SSH 访问入口查询远程登录的作业ID、代理域名、代理入口UUID,如下图所示:
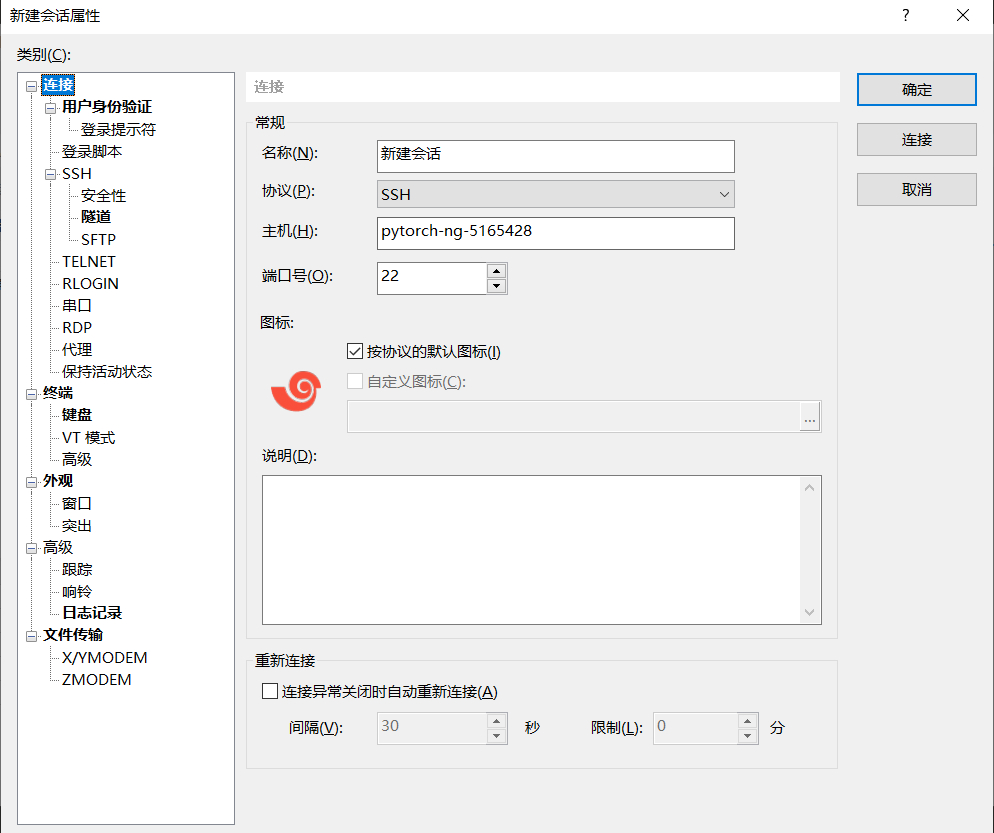
打开Xshell工具,“文件” \(\rightarrow\) “新建” 打开 “新建会话属性” 弹窗,按如下方式填写:
"主机" 处填写
作业ID(注意不能填写成proxy.nscc-gz.cn)"协议" 处选择
SSH"端口" 处填写
22
如下图所示:
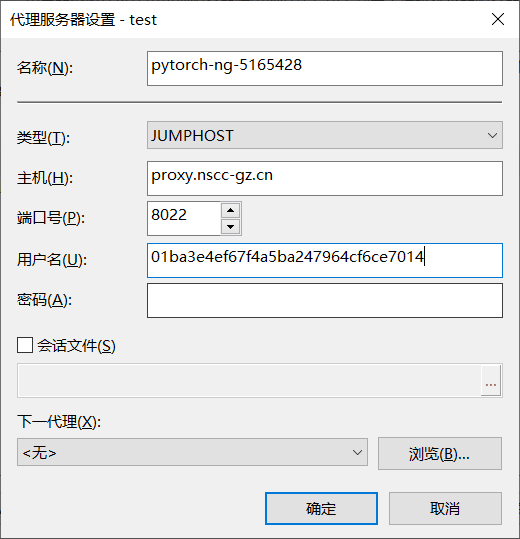
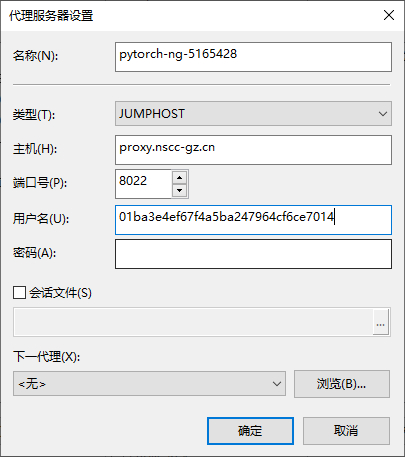
然后点击左侧菜单栏 “连接” 下的 “代理” 选项,点击窗口中 “代理服务器” 右方的 “浏览” 按钮打开 “列表代理” 窗口,点击 “添加” 按钮打开 “代理服务器设置” 窗口,在窗口中按如下方式填写:
"名称" 处可自定义一个名称,如
作业ID,用于区分不同的代理设置"类型" 处选择
JUMPHOST"主机" 处填写代理域名
proxy.nscc-gz.cn"端口" 处填写代理端口号
8022"用户名" 处填写
<入口UUID>
如下图所示:
接着点击 “确定” 返回 “列表代理” 窗口,点击关闭返回 “新建会话属性” 窗口,在 “代理服务器” 下拉列表选中刚才创建的代理设置,随后点击 “连接” ,按照提示输入星光用户名和密码或者使用密钥进行验证后,即可登录到作业运行的容器中。
备注
用户名 为星光用户名,可见 “作业详情” \(\rightarrow\) “基本信息” 中的 用户 项:
密码 为星光平台的登录密码。
Xftp¶
首先在 作业详情 的 SSH 访问入口查询远程登录的作业ID、代理域名、代理入口UUID,如下图所示:
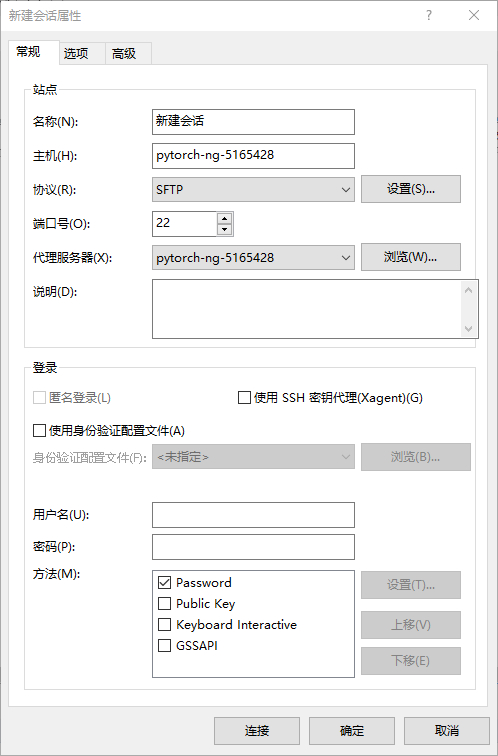
打开Xftp工具,“文件” \(\rightarrow\) “新建” 打开 “新建会话属性” 窗口,在窗口中按如下方式填写:
"主机" 处填写
作业ID"协议" 处选择
SFTP"端口" 处填写
22
如下图所示:
然后在 “代理服务器” 处点击右侧的 “浏览” 按钮打开 “列表代理” 窗口,点击 “添加” 按钮打开 “代理服务器设置” 窗口,在窗口中按如下方式填写:
"名称" 处可自定义一个名称,如
作业ID,用于区分不同的代理设置"类型" 处选择
JUMPHOST"主机" 处填写代理域名
proxy.nscc-gz.cn"端口" 处填写代理端口号
8022"用户名" 处填写
<入口UUID>
如下图所示:
接着点击 “确定” 返回 “列表代理” 窗口,点击关闭返回 “新建会话属性” 窗口,在 “代理服务器” 下拉列表选中刚才创建的代理设置,随后点击 “连接” ,按照提示输入星光用户名和密码或者使用密钥进行验证后,即可登录到作业运行的容器中。
备注
用户名 为星光用户名,可见 “作业详情” \(\rightarrow\) “基本信息” 中的 用户 项:
密码 为星光平台的登录密码。
PyCharm¶
PyCharm 连接容器前必须完成的准备工作
在使用 PyCharm 进行 ssh 连接前,请确保本地 PyCharm 软件为 最新版本,并检查本地是否配置有网络代理,若有请关闭,避免影响连接。
容器内互联网代理配置(必须):
PyCharm 与容器作业建立远程连接时,会在容器中先下载并安装 IDE 后端程序,后续的扩展下载等操作也都需要联网。由于容器环境内没有直接访问互联网的能力,因此必须先将集群上网代理配置进容器的 ~/.bash_profile 文件中,PyCharm 会通过该代理联网完成初始化和扩展下载,否则将无法成功建立远程连接。
通过 ssh 直接连接 进入容器作业,执行以下命令将代理配置加载进 ~/.bash_profile 文件中:
echo -e "\nsource /app/bin/proxy.sh" >> ~/.bash_profile
对 ~/.bash_profile 文件的修改,除了会影响当前作业之外,所有投递于当前作业所投递集群的作业也均会受到影响,所以在不需要时,请将 ~/.bash_profile 文件中的代理配置取消。
完成 ssh 精简命令连接 (手动配置 或 自动化配置 均可)后,即可在 PyCharm 中连接容器。
首先在 作业详情 的 SSH 访问入口查询远程登录的作业ID、代理域名、代理入口UUID,如下图所示:
打开PyCharm,点击 “File” \(\rightarrow\) “Remote Development” 打开 “Remote Development” 窗口,如下图所示:
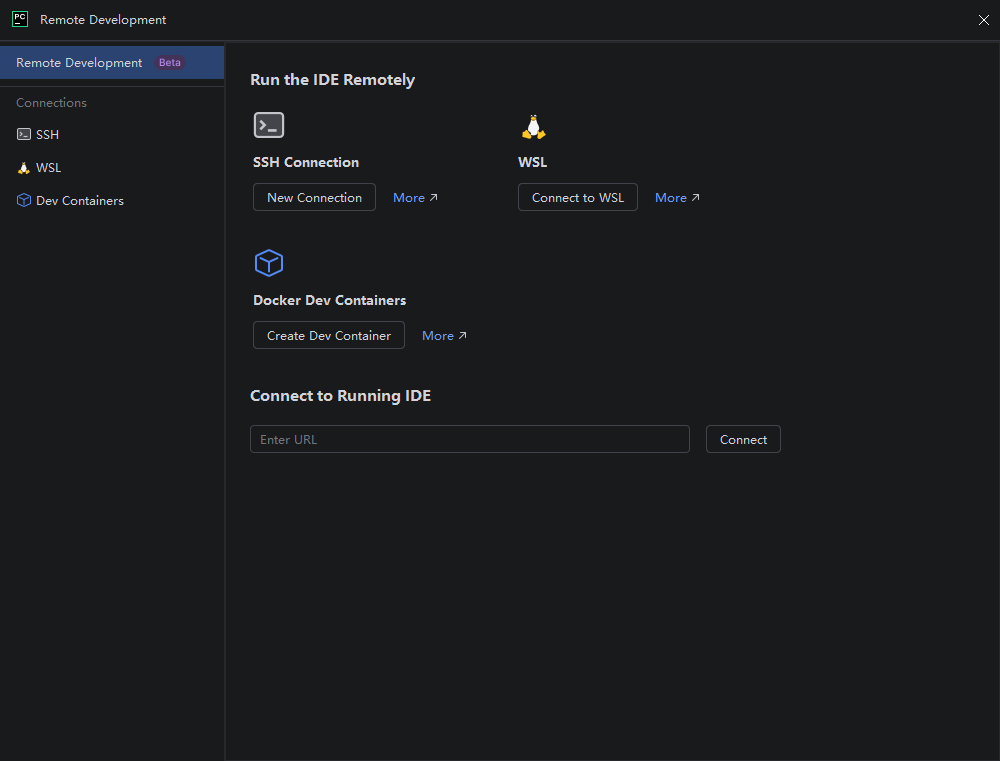
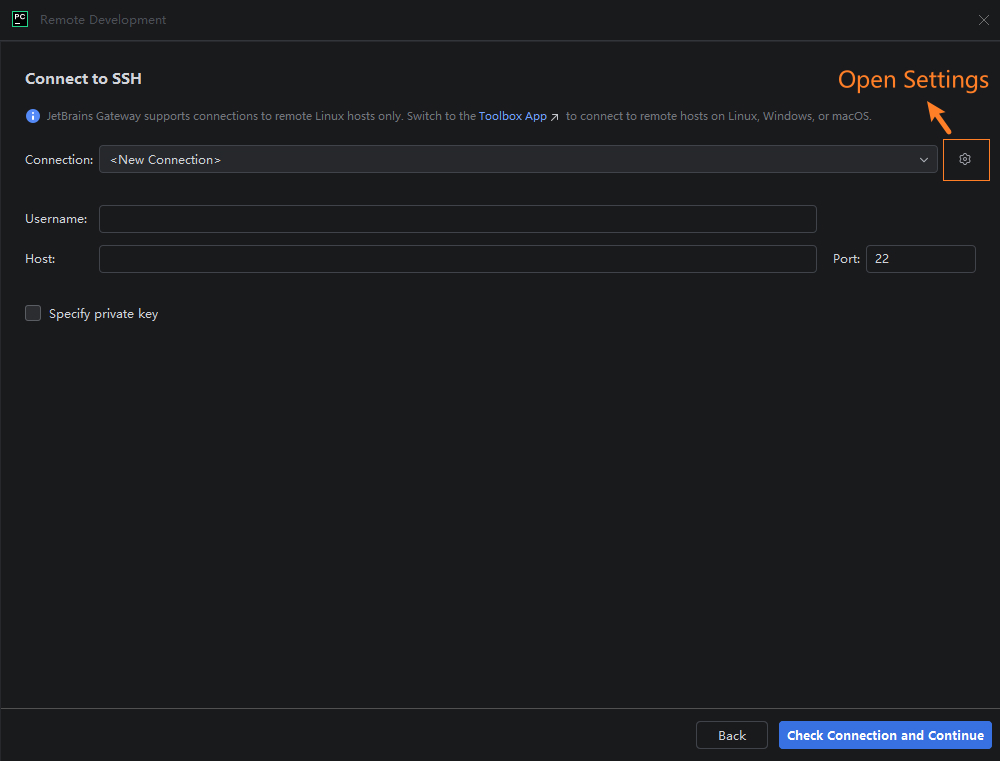
在 “SSH connection” 下点击 “New Connection”,点击 “Connection” 右侧的设置图标(Open Settings),如下图所示:
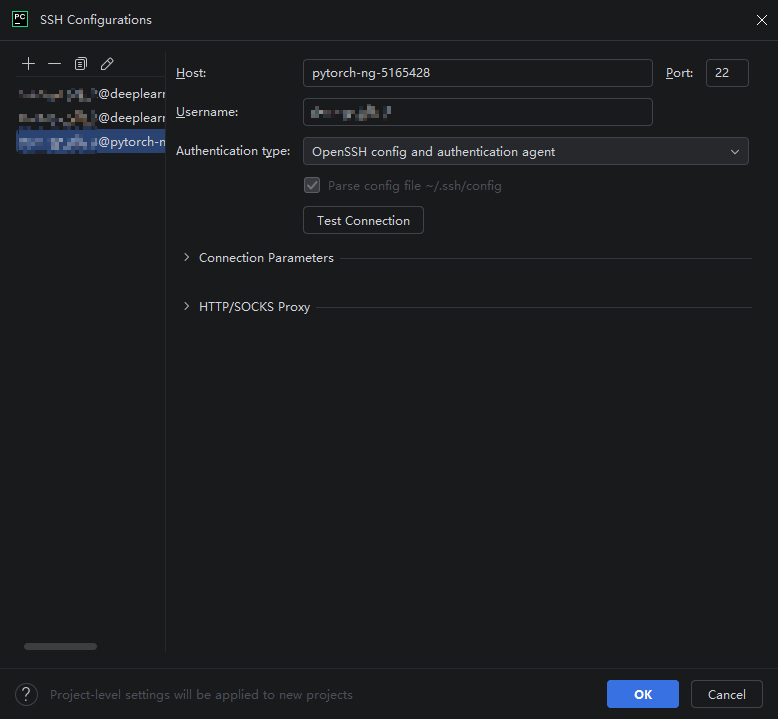
在弹出的 “SSH Configuration” 窗口中,点击左上角的 “+” 按钮新建一个 SSH 配置,按如下方式填写:
"Host" 处填写
<作业ID>"Port" 处填写
22"Username" 处填写您的星光用户名
"Authentication type" 处选择 “OpenSSH config and authentication agent”
如下图所示:
备注
可以点击 “Test Connection” 按钮测试连接,若提示需要验证密码则输入星光密码并点击 “Next”,出现 “Successfully connected!” 则表示连接成功。
点击 “OK” 按钮返回 “Remote Development” 窗口后,在 “Connection” 下拉列表中选中刚才创建的 SSH 配置,再点击 “Check Connection and Continue” 按钮(若提示需要验证密码则输入星光密码并点击 “Authenticate”),即可进入 “Choose IDE and Project” 窗口。
在该窗口中,需要在 “IDE version” 下拉列表中指定要下载到容器的 PyCharm 版本,在 “Project directory” 中指定容器上的项目路径,如下图所示:
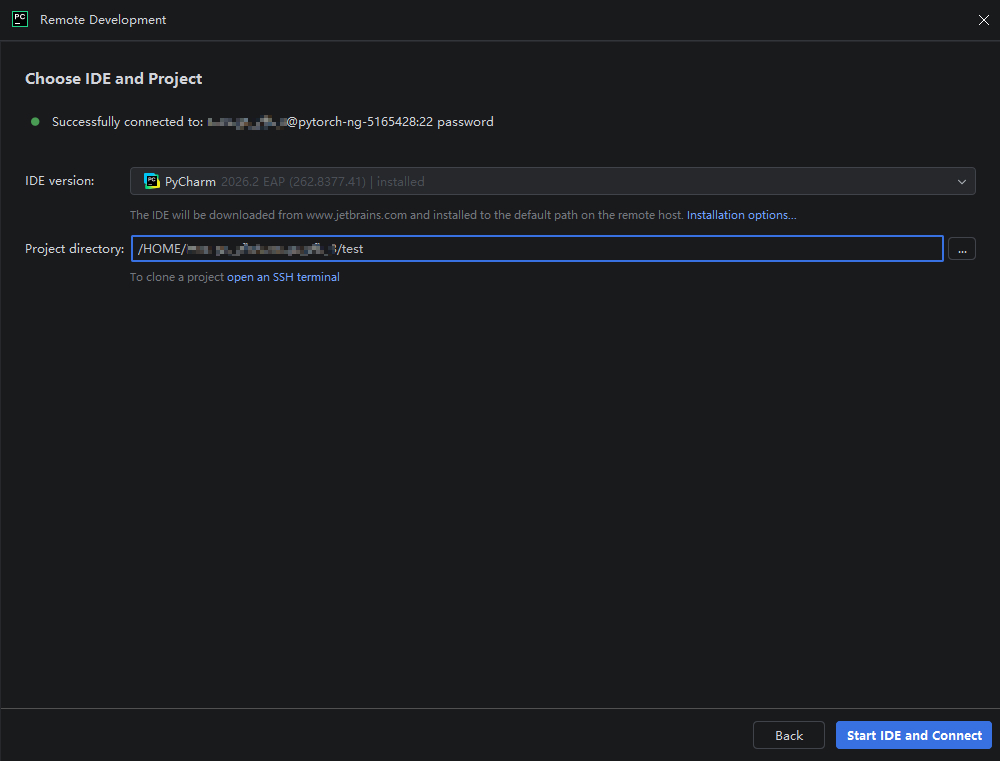
指定完成后,点击 “Start IDE and Connect” 按钮,PyCharm 会在容器中联网下载并安装指定版本的 PyCharm IDE 后端(由于安装包较大,约 500MB 以上,因此第一次连接时需要等待一段时间),安装完成后会自动打开远程开发 PyCharm IDE 界面
备注
若在 IDE 后端下载或安装过程中遇到错误,请参考 PyCharm 远程 IDE 后端下载安装常见错误。
在远程开发 PyCharm IDE 界面中可进行代码编辑、调试、运行等操作,如下图所示:
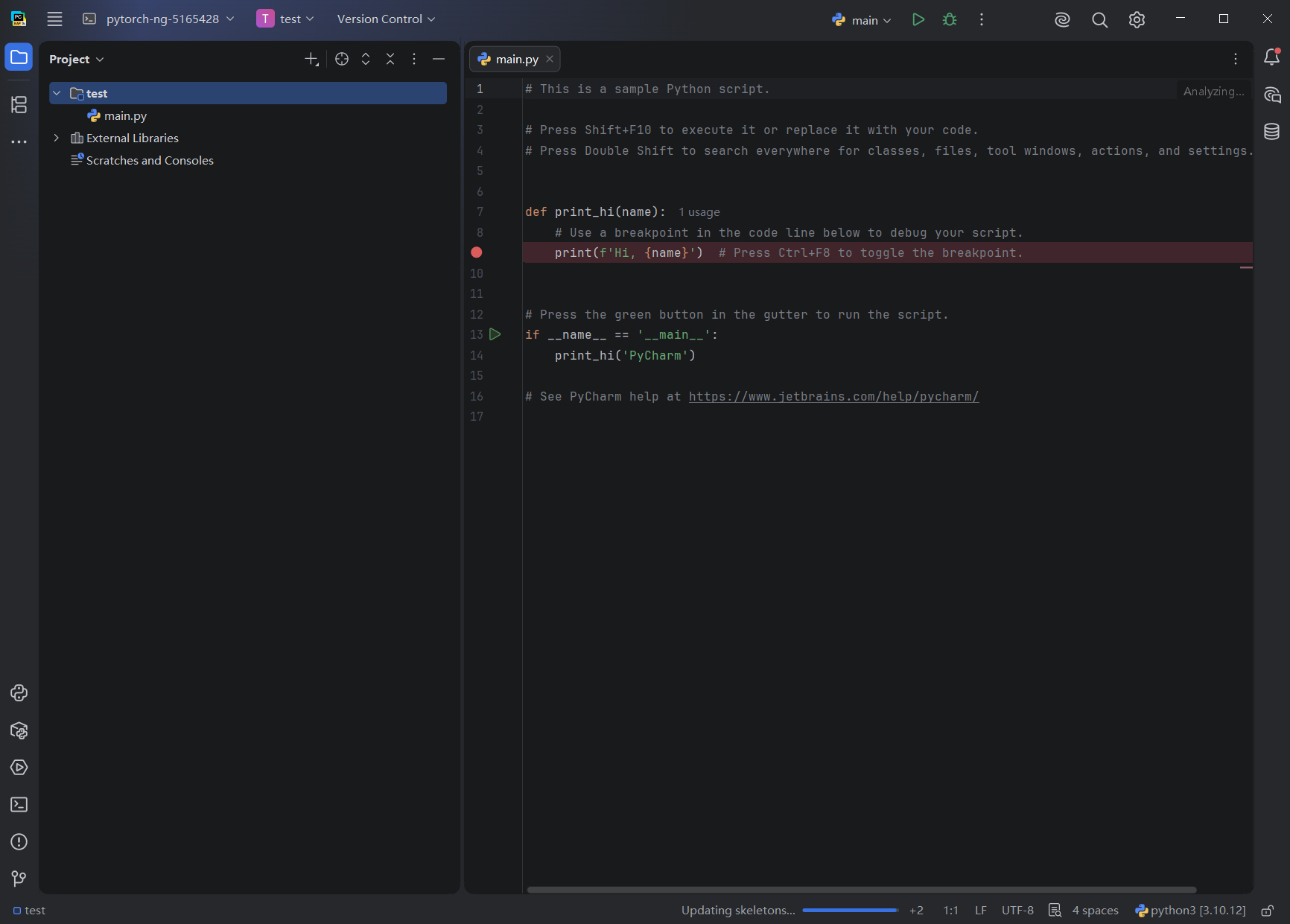
更多关于从 PyCharm 通过 SSH 连接到远程服务器的使用,请参考官方文档:https://www.jetbrains.com/zh-cn/help/pycharm/remote-development-starting-page.html#start_from_IDE
AI 训练守护¶
AI 训练任务启动方式¶
用户可在自己的作业中使用平台提供的 starlight-executor 执行器来启动自己的 AI 训练任务,这样平台会自动定时监测 AI 训练任务的状态(如训练任务是否卡住、训练性能是否下降等),并提供在检测到异常时自动重启恢复 AI 训练任务或者自动终止 AI 训练任务的功能(可通过配置文件设置)。
备注
starlight-executor 执行器所在的路径在容器作业内为 /app/ai/bin/starlight-executor,在 slurm 作业内为 /APP/ai/bin/starlight-executor。
小技巧
可通过命令
export PATH=/app/ai/bin:$PATH # 在容器作业内
export PATH=/APP/ai/bin:$PATH # 在 slurm 作业内
将 starlight-executor 执行器添加到环境变量中,方便后续的使用。
配置文件可通过如下命令交互式生成:
starlight-executor --gen-config
下面是一份示例配置文件:
# 配置文件示例
starlight_executor:
debug: false # 是否输出调试信息
id: 2501001-01 # 任务标识
count: 2 # 任务并发度
rules: # 日志采集规则
- rule: .log # 日志采集规则,采集所有后缀为 .log 的日志文件
prefix: false # 是否使用前缀匹配来匹配日志文件
support_restart: true # 训练任务是否支持重启恢复
performance_detect: true # 是否开启性能检测
debug_cupti: false # 是否生成cupti性能数据文件
auto_fault_handling: true # 是否启用自动故障处理
feature_disable_options: # 禁用的诊断功能
ib: true # 是否禁用IB诊断
gpu_utilization: false # 是否禁用GPU利用率诊断
gpu_fp_utilization: true # 是否禁用GPU FP单元诊断
gpu_tensor_utilization: false # 是否禁用GPU Tensor诊断
gpu_sm: false # 是否禁用GPU SM单元诊断
gpu_memory: false # 是否禁用GPU显存诊断
gpu_temperature: false # 是否禁用GPU温度诊断
gpu_power: false # 是否禁用GPU功耗诊断
gpu_pcie: false # 是否禁用GPU PCIe诊断
gpu_nvlink: false # 是否禁用GPU NVLink诊断
cpu_utilization: false # 是否禁用CPU利用率诊断
memory: false # 是否禁用内存诊断
lustre: false # 是否禁用Lustre诊断
logical_disk: true # 是否禁用逻辑磁盘带宽诊断
prompt: | # 自定义诊断提示词
训练框架用的是LLaMA-Factory, 训练过程会不断输出和更新进度条, 格式为"完成率 | 已完成迭代数/总迭代数 [训练时间, 预估完成 时间, 全局迭代速度]", 其中完成率=已完成迭代数/总迭代数*100%, 全局迭代速度=已完成迭代数/训练时间, 预估完成时间=剩余迭代数/ 全局迭代速度。从检查点恢复训练任务时,由于已完成迭代数包含检查点累积的步数,而训练时间不包含检查点累积步数的训练时间,而是恢复 训练后从零开始累积的时间, 这会导致随着训练不断进行, 全局迭代速度也在不断下降, 但真实迭代速度并没有太大的变化。比如从包含1000 0步训练结果的检查点恢复后, 经过20秒到10001步, 全局迭代速度=10001/20≈500it/s, 真实迭代速度=1/20=0.05it/s, 再经过100 秒到10005步, 全局迭代速度=10005/100≈100it/s, 真实迭代速度=(10005-10000)/100=0.05it/s, 再经过10000秒到10500步, 全 局迭代速度=10500/10000≈1it/s, 真实迭代速度=(10500-10000)/10000=0.05it/s, 全局迭代速度不断下降,预估完成时间也在不断 增长, 但是真实迭代速度其实不变。若只从全局迭代速度判断训练异常并不断重启, 有可能导致永远无法训练到新的检查点, 训练永远无法 结束。诊断时应该算出真实速度, 真实速度没有显著下降则应判断训练仍在正常进行, 并且模型较大时单步训练时间会很长(如分钟级, 真实迭 代速度可能低于0.01it/s), 不要因为真实速度太低而判断训练卡住。另外需要注意的是当全局迭代速度下降到小于1it/s时, 训练框架会直 接用单个迭代的时间来表示全局迭代速度, 即速度单位从it/s换成了s/it, 预估完成时间=剩余迭代数*全局迭代速度。
备注
配置文件说明:
id为唯一任务标识,用于在平台中标识该 AI 训练任务。每次启动starlight-executor执行器开始新的训练任务时,需要重新指定一个唯一的任务标识,否则会启动失败。count为任务并发度,用于指定该 AI 训练任务的并发进程数。若用户的 AI 训练任务需要在多台机器上并行运行,则需要将count项设置成与 AI 训练任务的总进程数一致。rules为日志采集规则,用于指定starlight-executor执行器需要自动采集的日志文件。用户可以根据自己的需求,添加或删除日志采集规则,日志采集规则最多设置 8 条。每条规则都可以单独设置使用前缀或者后缀来匹配日志文件名:若使用前缀匹配,则设置prefix为 true;若使用后缀匹配,则设置prefix为 false。support_restart用于说明 AI 训练任务是否支持重启恢复。若设置为 true,则当训练任务异常时,平台会自动重启该训练任务;若设置为 false,则当训练任务异常时,平台会自动终止该训练任务。auto_fault_handling用于设置平台检测到训练任务异常时是否需要真正执行自动重启或者自动终止训练任务操作。performance_detect用于设置平台是否需要自动检测 CUDA kernel 的运行性能是否正常。feature_disable_options用于设置是否禁用掉部分性能数据的诊断。prompt用于设置自定义的诊断提示词,最好是对 AI 训练任务及使用的框架进行详细的说明。
对于同一个 AI 训练任务的不同进程,都需要使用执行器进行启动,并使用同一份配置文件。
训练任务的标准输出和标准错误输出会自动采集,无法禁用此功能。
通过 starlight-executor 启动 AI 训练任务的方式如下:
export starlight_executor_config=配置文件的路径
starlight-executor <训练任务命令> <训练任务参数>
小心
必须通过环境变量
starlight_executor_config来指定配置文件的路径。训练任务命令和参数的格式与直接在命令行中运行相同。
通过 starlight-executor 启动多机多卡 AI 训练任务的方式如下:
# 节点1
export starlight_executor_config=配置文件的路径
starlight-executor <训练任务命令> <训练任务参数1>
......
# 节点n
export starlight_executor_config=配置文件的路径
starlight-executor <训练任务命令> <训练任务参数n>
小心
每个节点上的
starlight-executor执行器需要使用同一份配置文件,配置文件里面的count需要跟执行的starlight-executor执行器的数量一致。每个节点上的
starlight-executor执行器可以使用不同的训练任务参数。
AI 训练任务查看方式¶
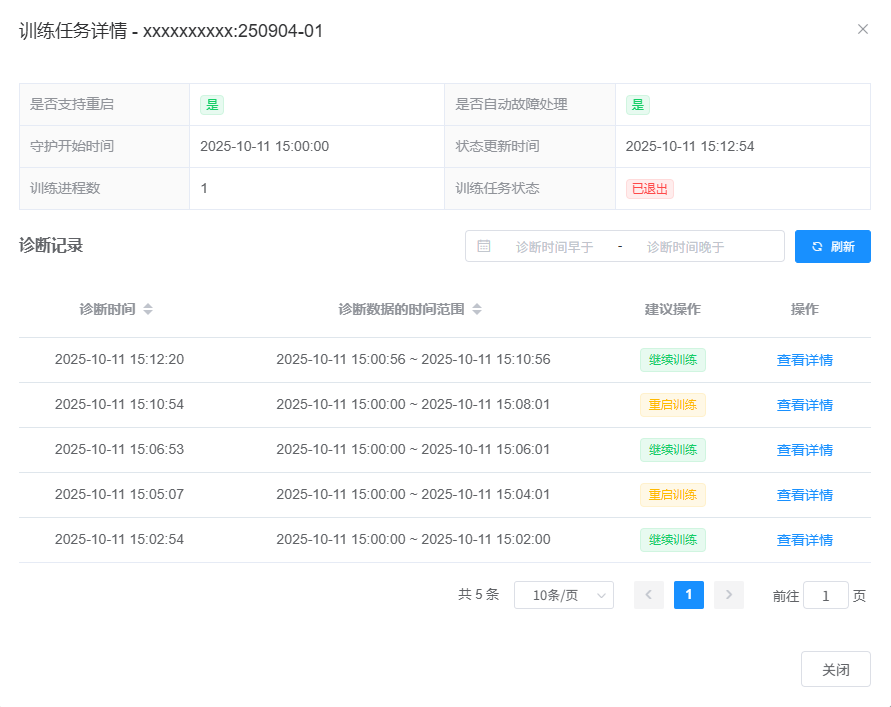
当在作业中使用 starlight-executor 启动 AI 训练任务后,用户可在 作业详情 页查看 AI 训练任务的自动定时诊断情况,如下图所示。
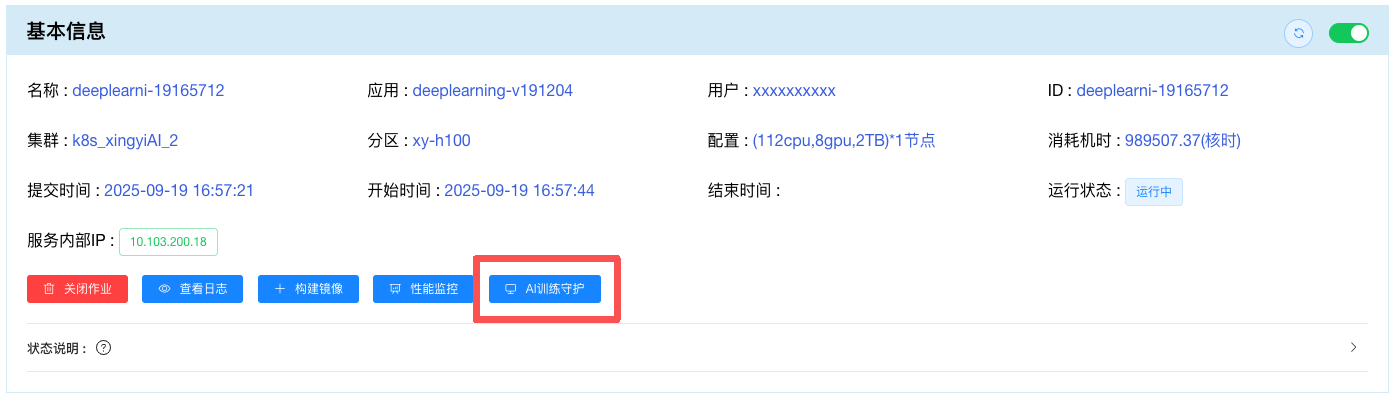
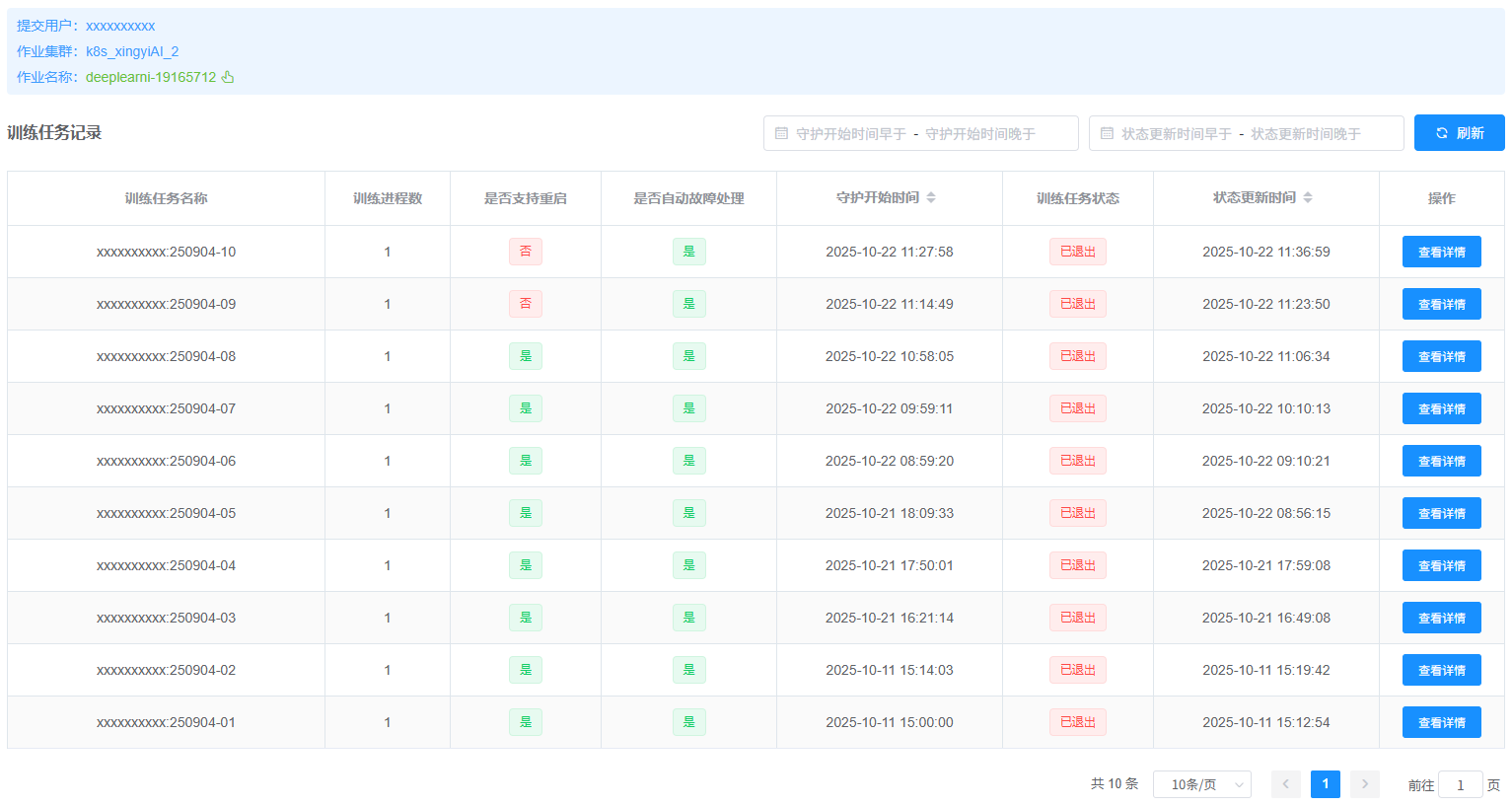
点击 “AI训练守护” 按钮会自动跳转到 AI 训练守护的页面,用户可以在该页面查看 AI 训练任务的自动定时诊断信息。
小技巧
可按照 AI 训练任务的 “守护开始时间” 和 “状态更新时间” 来排序 AI 训练任务的列表。
可点击 “刷新” 按钮,手动刷新 AI 训练任务的列表。
列表中训练任务的个数与您在作业中使用
starlight-executor启动的 AI 训练任务次数相关(每次启动时需要更新配置文件,设置新的唯一id)。
点击 “查看详情” 按钮可以查看该 AI 训练任务的详细信息,包括每次自动诊断的结果,如下图所示。
小技巧
可按照 “诊断时间” 来排序诊断记录列表。
可点击 “刷新” 按钮,手动刷新诊断记录的列表。
“建议操作” 中的
重启训练和终止训练不一定会自动执行,除非配置文件中auto_fault_handling设置为 true,并且连续两次的诊断结果都一致,平台才会自动执行该操作。
点击 “查看详情” 按钮可以查看该诊断记录的详细信息,包括诊断的时间、诊断的结果、诊断使用的指标等。
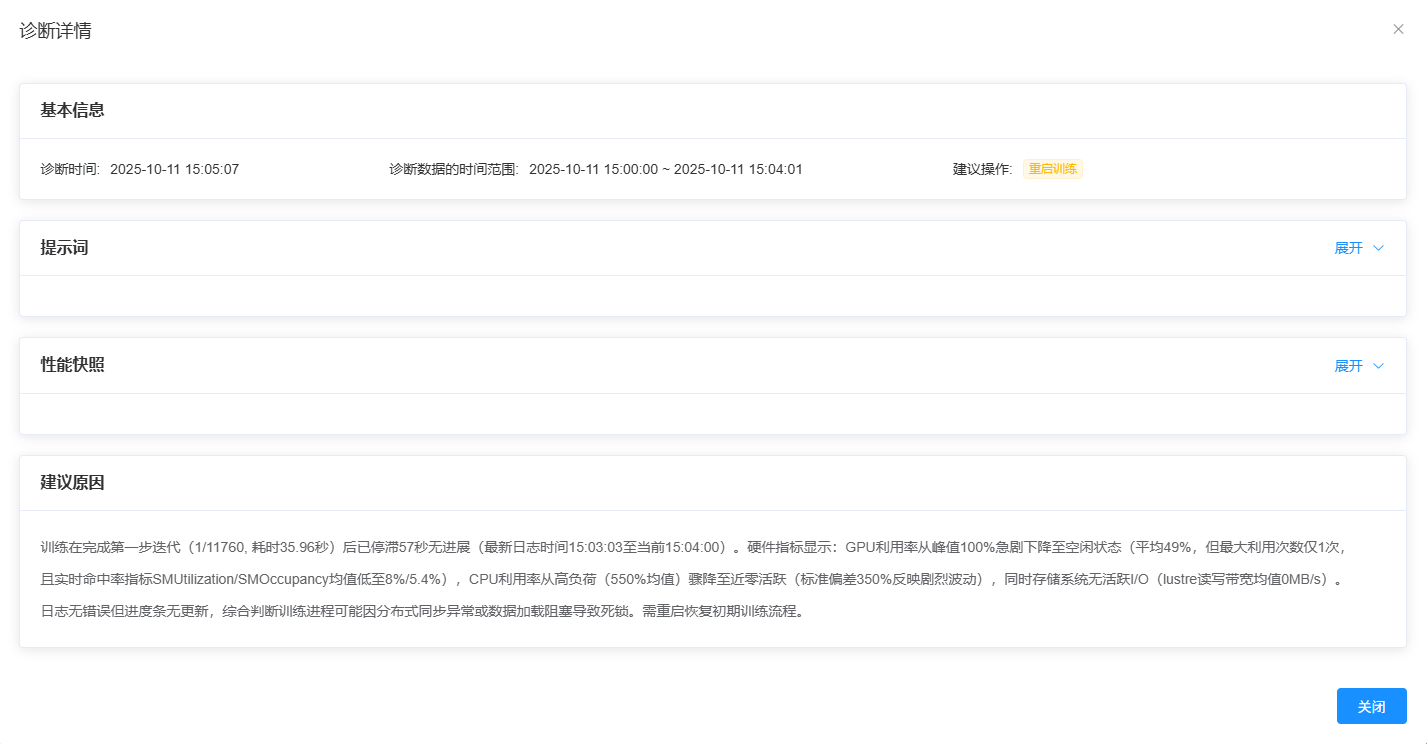
小技巧
可点击 性能快照 的 “展开” 按钮,查看诊断时所用的性能指标数据(只有需要重启或终止训练时才能查看性能快照)。
工作流任务¶
平台左侧导航栏中点击 “工作流任务”,进入工作流作业管理界面。
点击 “查看” 按钮进入对应的 “工作流运行” 页面。
双击 “开始” 节点,显示提交的输入参数;
双击 “结束” 节点,显示工作流运行结束后的输出数据;
双击 “步骤” 节点,显示对应的步骤详情。
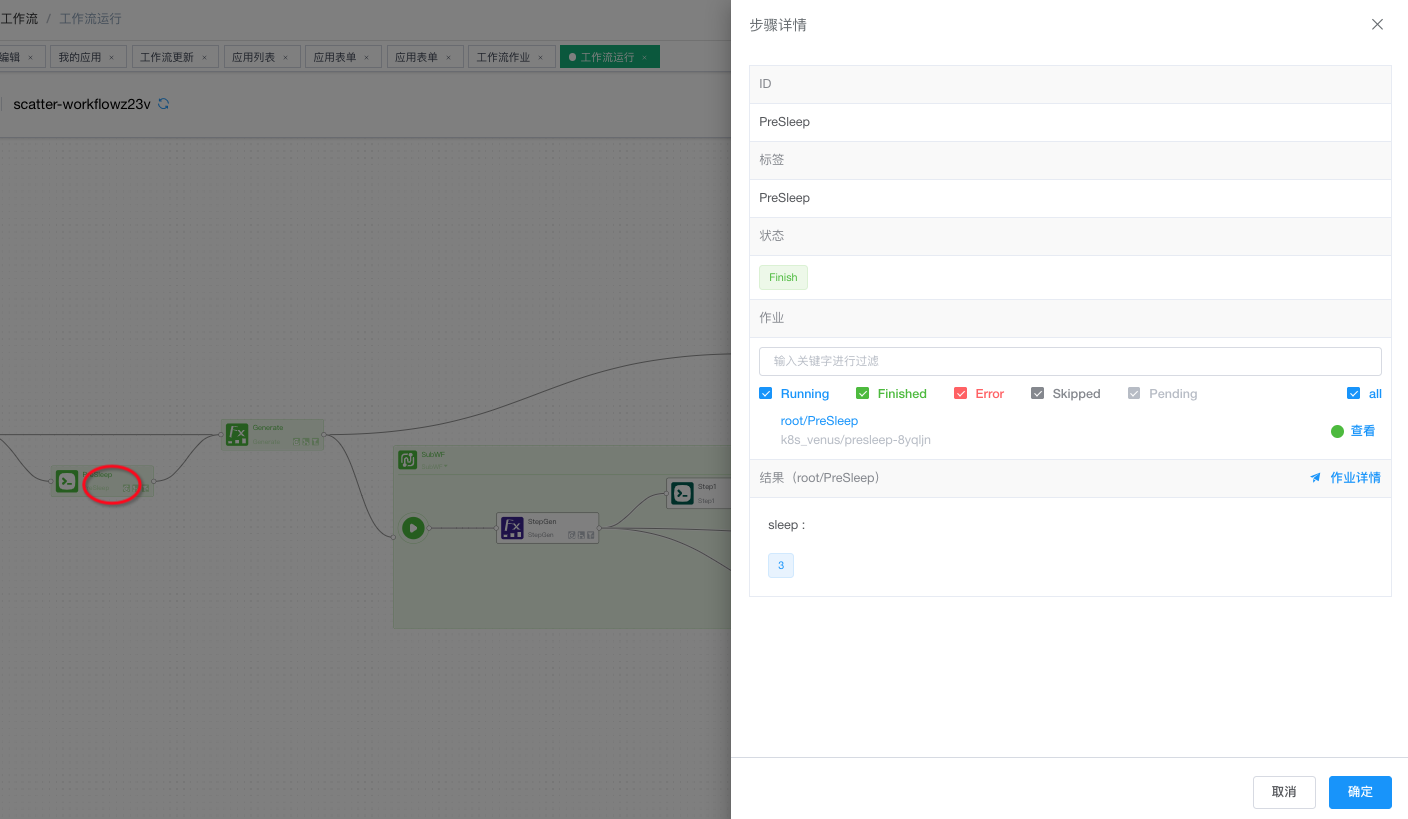
对于进行了分发的嵌套子工作流,可以点击步骤图框的标题栏上的下拉按钮,查看不同分发流程的执行情况,并可以选择其中具体某一个流程进行进一步的查看:
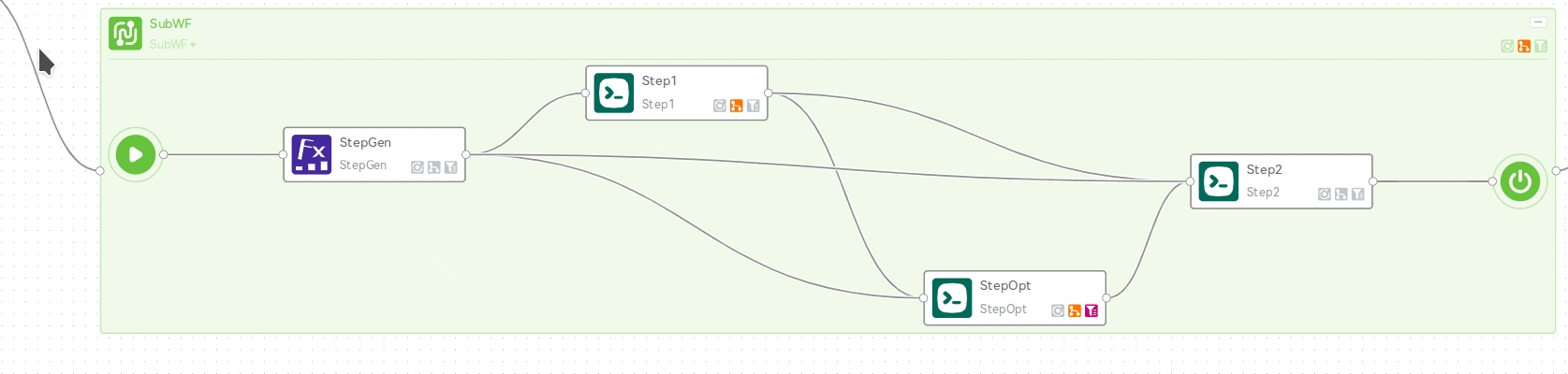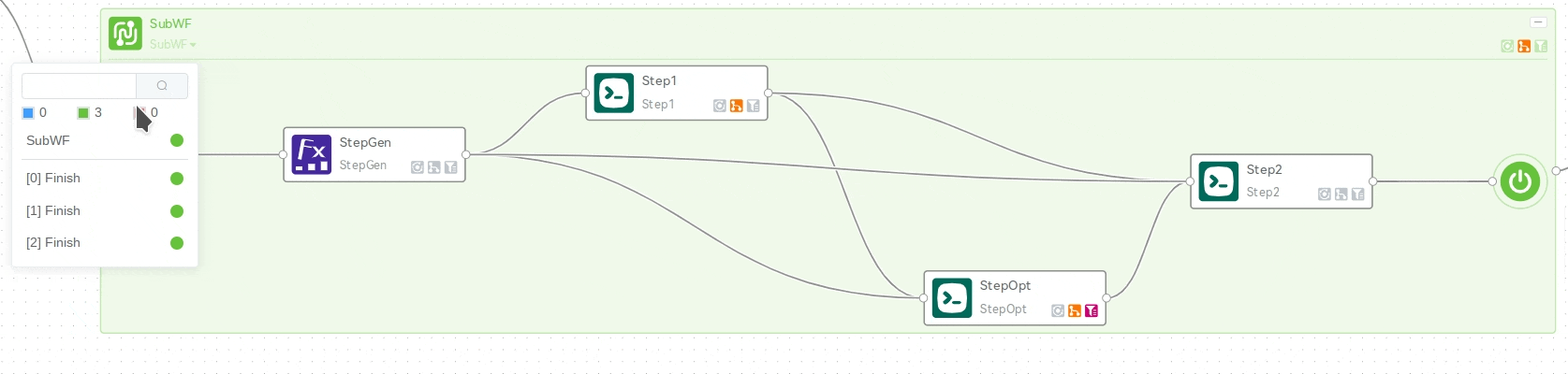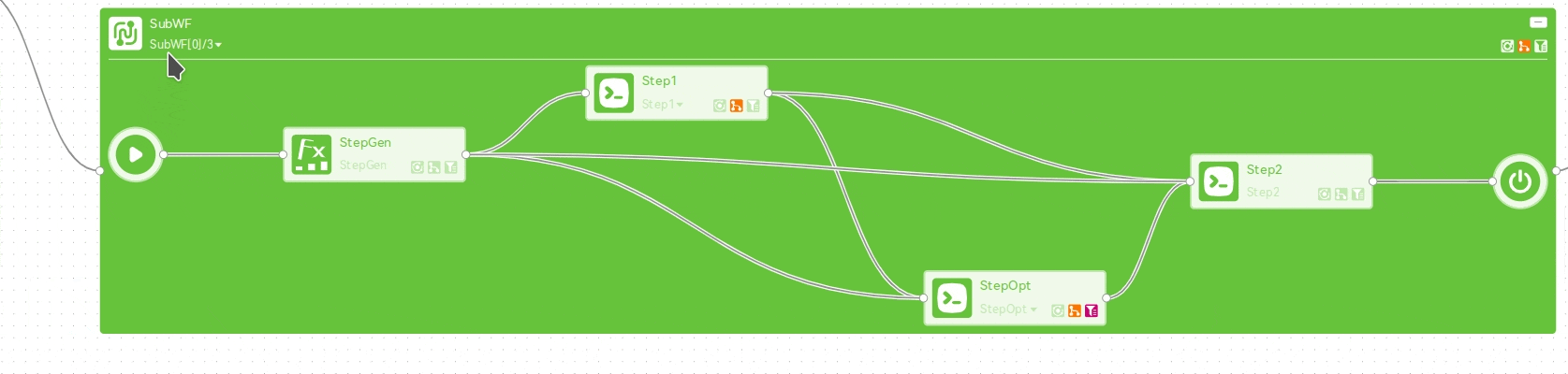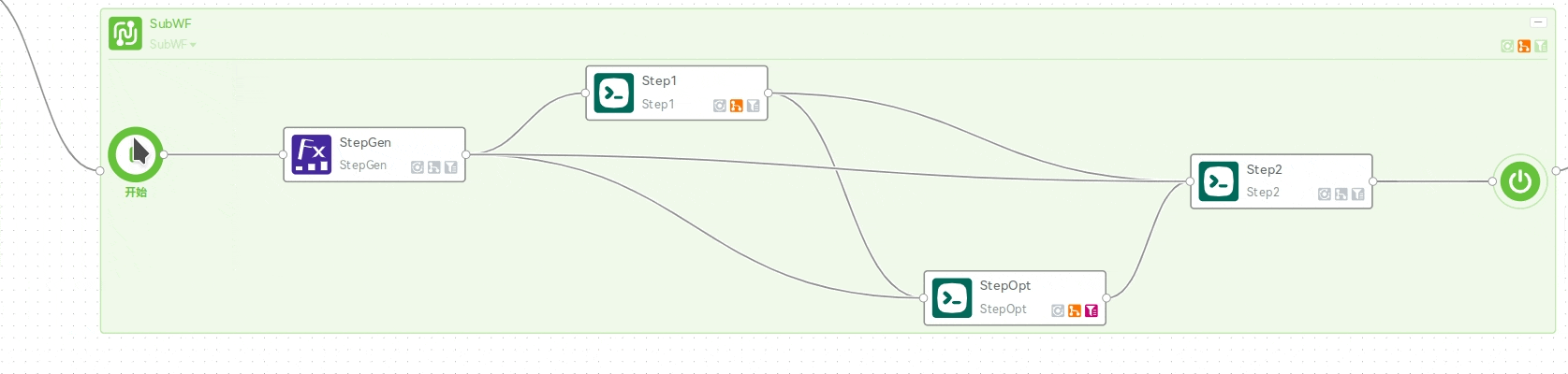
也可以双击展开步骤详情页,在作业列表栏中逐级查看:
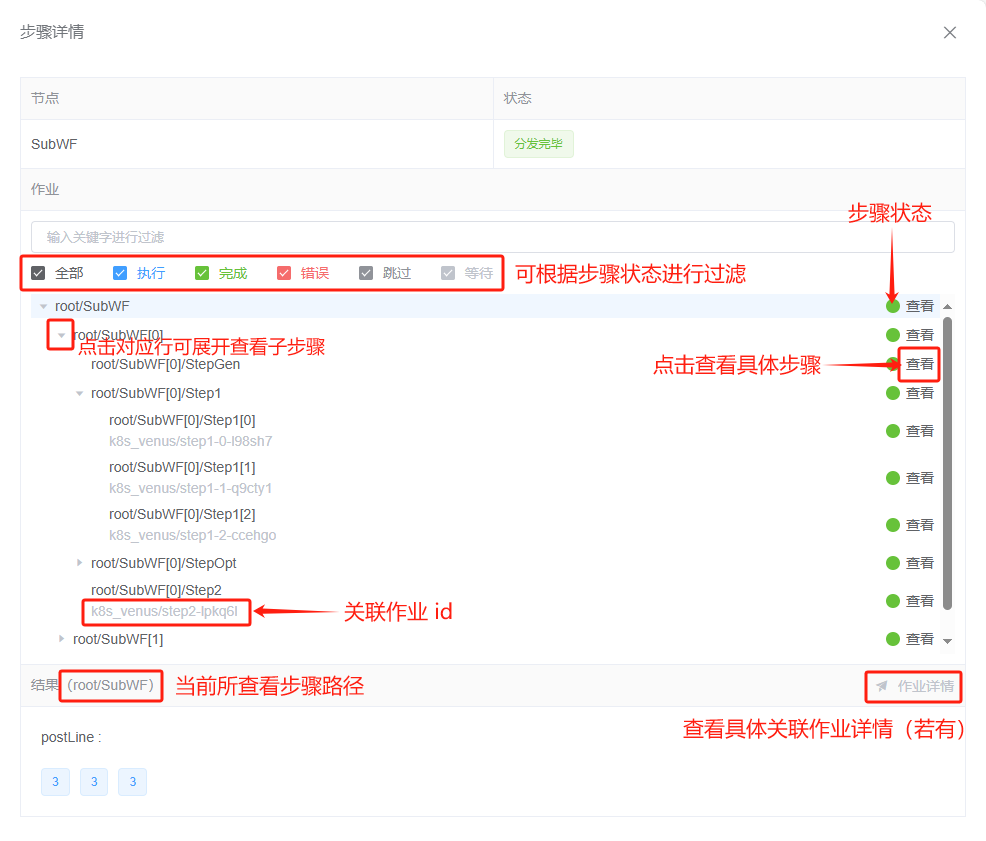
如果查看的节点能关联到具体的作业,可以点击 “作业详情” 链接进行跳转查看。
对于还在执行的工作流,可以通过右上角的按钮进行流程的暂停、恢复、终止。
暂停
流程不再继续执行,但可以恢复。
恢复
流程恢复继续执行。
终止
流程不再继续执行,不可以恢复。等待所有仍在运行的步骤结束后释放所有资源。